
Quick Answer
Start by treating zapier for freelancers as an operations system, not a one-time setup. Define ownership, approval points, allowed fields, and manual fallback steps before go-live, then launch only a small set of high-value workflows. Use impact-based triage when something fails, pause the affected path, and recover in a replay-safe order to avoid duplicates. If maintenance becomes unclear or multi-app logic keeps breaking, use Hire an Expert rather than forcing more complexity.
Stop Juggling Apps and Start Running a Professional Freelance System#
If your stack feels messy, the fix is usually not one more app. Zapier works best here as the connective layer in your business, so client work, paperwork, invoicing, and follow-up keep moving without you babysitting every handoff.
Choose functions before tools#
Start by naming the jobs your setup must handle: intake, signatures, delivery, invoicing, and accounting. Zapier's own 2026 freelancer roundup maps tools by function, with examples like Wave for invoicing, DocuSign for electronic signatures, and FreshBooks for accounting. That is the right place to start. Choose one tool for each job, then connect the handoffs.
A quick check helps. If you cannot point to the single place where a new lead, signed agreement, or paid invoice should land, you are not ready to automate yet. Admin work already eats into paid work. The goal is not more software. It is fewer manual handoffs you have to remember.
Define the connection you are willing to own#
Treat each automation connection as something you own end to end. Before you turn anything on, decide four things on paper: who owns it, where a human must approve something, what data should not move, and what you will do manually if it fails.
When the setup is unclear, ownership gaps, duplicate records, and avoidable data movement show up fast.
| Area | Ad hoc behavior | System behavior | What you do next |
|---|---|---|---|
| Intake | Copy lead details by hand | New inquiry lands in one chosen place | Test with one real form submission |
| Delivery | Track status from memory | Handoffs create the next task consistently | Check that the right assignee and due date appear |
| Invoicing | Invoice only when you remember | Billing starts from a defined milestone | Verify one completed job creates one invoice prompt |
| Incident handling | Notice problems late | One owner checks exceptions and fixes them | Keep a short fallback step for each connection |
Use this section as your filter#
Use this as a filter before you touch any settings. No single app will organize your business by itself, and productivity is personal. Set the rules first, then turn those rules into build decisions, prep work, and launch steps in the sections that follow.
Should You Build It Yourself or Hire a Zapier Specialist#
Choose based on operational ownership, not confidence. If you cannot reliably monitor, fix, and safely replay a workflow, do not own it alone.
| Process | Build it yourself when | Bring in help when | Maintenance owner signal |
|---|---|---|---|
| Lead intake | One form creates one record in one destination | You branch routing by service, source, or availability with Paths | You can run weekly test submissions and duplicate checks |
| Contract flow | A signature only updates status or creates one task | A signature triggers multiple downstream actions across apps | A missed handoff could delay client start, so ownership must be explicit |
| Invoicing | Delivery completion creates one invoice prompt or draft | Billing includes milestones, exceptions, or client-specific rules | You can review failed runs and replay without creating bad records |
| Payment sync | A paid event updates one finance record | One payment event touches bookkeeping, delivery, and client comms | Errors could create duplicate entries or heavy cleanup |
- Map complexity first. Label each workflow
linearorbranching. If you usePaths, treat each branch as its own test path.
Decision artifact: a simple map plus a named owner for each workflow.
- Classify business risk. Keep lead intake as lower risk. Treat contract flow, invoicing, and payment sync as higher risk when failures affect commitments or money. If admin work is already more than 20 percent of your time, treat that as a strong signal to scope outside help.
Decision artifact: a short high-risk list with owner names.
- Set support boundaries. Decide whether you will review run history, debug errors, and handle partial failures without creating duplicates.
Decision artifact: a written boundary for what you maintain, what an expert maintains, and when escalation happens.
- Run a limited pilot before rollout. Use one live workflow that matters but will not damage billing if it fails. If you hire help, use Zapier's Hire an Expert path, choose generalist or specialist based on your workflow type, and verify Expert badge/title in Zapier Community.
Decision artifact: a written go/no-go rule based on one week of clean runs.
Once this decision is locked, move to production prep: fields, owners, approvals, and fallback steps.
What to Prepare Before You Build Your First Production Zap#
Treat this as pre-onboarding: define scope, owners, boundaries, and fallback steps before you build. That upfront prep keeps your first production Zap reliable instead of fragile.
Map each process and rate the failure impact#
List the workflows you plan to automate first, then assign ownership and failure impact before touching the build. For each workflow, name the start point, end point, owner, approver, and what breaks if it fails.
| Process | Start point | End point | Owner | Approver | Criticality if it fails |
|---|---|---|---|---|---|
| Lead intake | Form or scheduler | CRM, inbox, or task list | You | You or ops support | Medium: missed or delayed follow-up |
| Client onboarding | Signed agreement or intake form | Project board, welcome email, kickoff task | You | You | High: poor handoff can stall early momentum |
| Delivery to invoice | Completed task or status change | Invoice draft or billing queue | You | Finance reviewer if you use one | High: delayed billing or wrong invoice timing |
| Payment update | Payment confirmation | Accounting record, project status, client message | You | Finance reviewer if you use one | High: duplicate records or inaccurate status |
Use a simple prep rule: low-impact workflows can stay light, but any workflow tied to client commitments or revenue needs full prep. Verification point: every planned automation has a named owner, approver, and failure impact.
Define boundaries and data before field mapping#
Define the boundaries before data starts moving. For each workflow, classify fields into three practical buckets:
| Field bucket | Description |
|---|---|
| Required fields | Minimum data needed for the handoff to work |
| Restricted fields | Only pass when the workflow truly needs them |
| Prohibited fields | Data you do not allow this automation to move |
Then classify fields for each workflow into three practical buckets:
- Required fields: minimum data needed for the handoff to work.
- Restricted fields: only pass when the workflow truly needs them.
- Prohibited fields: data you do not allow this automation to move.
Keep this practical, not pseudo-legal. Document the field decisions now, then add jurisdiction-specific handling only after you verify what applies to your business and client locations. Verification point: each workflow has an allowed-field list and a blocked-field list.
Name every build so triage is fast later#
Use one naming pattern every time so triage is faster later: purpose, system handoff, environment, and version. Example: Client Onboarding | Intake Form to Project Board | Live | v1.2
This is a traceability habit, not a Zapier product requirement. Put purpose first, then handoff, then environment, then version, and keep a short change note with date, editor, and change summary. Verification point: from the name alone, you can tell what it does, where data goes, and whether it is the current live version.
Write the fallback checklist before go-live#
Create a short runbook for every high-impact workflow before launch. At minimum, answer these questions:
| Runbook item | Question |
|---|---|
| Trigger symptom | What tells you the handoff failed? |
| Containment action | What do you pause first? |
| Manual workaround | How do you complete the client-facing task without automation? |
| Replay rule | When is rerun safe, and what must be checked first? |
| Owner sign-off | Who confirms recovery and closes the issue? |
Write the answers down before launch, not after the first miss.
Before any replay, run duplicate checks first: confirm whether the destination record already exists and whether the client already received the message, task, or invoice.
If you complete this prep first, your build starts with clear operating boundaries. Next, decide launch order: which automations go live first, and why.
What Are the First Automations Freelancers Should Launch#
Start with a small launch set, not everything at once: intake first, then agreement completion, then invoicing, then payment matching, and finally a scheduled operations summary. In practice, go live with only 2-3 workflows first, confirm they run cleanly, then add money-related handoffs.
Before You Start#
Use these as launch gates for each workflow:
- Owner and approver are named for any workflow that changes client status or touches billing.
- Source-of-truth fields are confirmed across connected apps, and each app is connected and authorized before testing.
- Rollback is defined: what to pause, how to complete the task manually, and what to check before rerunning.
| Order | Trigger example | Action example | Failure risk | Verification signal |
|---|---|---|---|---|
| 1 | New form submission | Create or update a lead record and send acknowledgment | Low | Each inquiry is captured and organized once |
| 2 | Agreement marked complete | Update client status and file the signed agreement | Medium | Completed agreement is easy to find in the client record |
| 3 | Delivery marked complete | Create an invoice draft or route to billing queue | High | One completion event produces one draft item |
| 4 | Payment confirmed | Update the existing invoice/accounting record by reference | High | Payment maps to the correct invoice record |
| 5 | Scheduled summary run | Compile leads, signed clients, draft invoices, and unmatched payments | Medium | You get one clear exceptions list to review |
-
Start with intake routing. A trigger is the event that starts the workflow, and an action is what runs after it. Use a stable identifier, for example email, so repeat submissions update the same lead instead of creating duplicates. If you send an automatic reply, personalize it so it does not read like a template blast.
-
Move next to agreement completion updates. When your e-signature tool marks an agreement complete, update the client record and store the file in its final location. Keep downstream project work tied to completion, not earlier statuses.
-
Trigger invoicing from a clear completion marker. Define your completion condition in the delivery tool first, then create a draft invoice or billing queue item on first pass. Keep a manual review point before anything client-facing is sent.
-
Sync payments with match-first logic. Match incoming payments to existing records using the same reference already used upstream. Prefer create-or-update patterns over blind new-record creation, and route unmatched items to manual review.
-
Finish with a scheduled operations summary. Pull the signals that show whether launch workflows are healthy: new leads, completed agreements, draft invoices, and payments that did not match cleanly.
Launch is phase one. After go-live, move directly into controls and recovery so your automations stay reliable as volume grows.
We covered this in detail in The Best Zapier Workflows for Freelancers.
How Do You Add Compliance and Audit Controls Without Slowing Down#
Add controls only at high-impact moments. Keep low-risk handoffs fast, then place review, tighter field mapping, and evidence capture only where a step can change money, contracts, or client records.
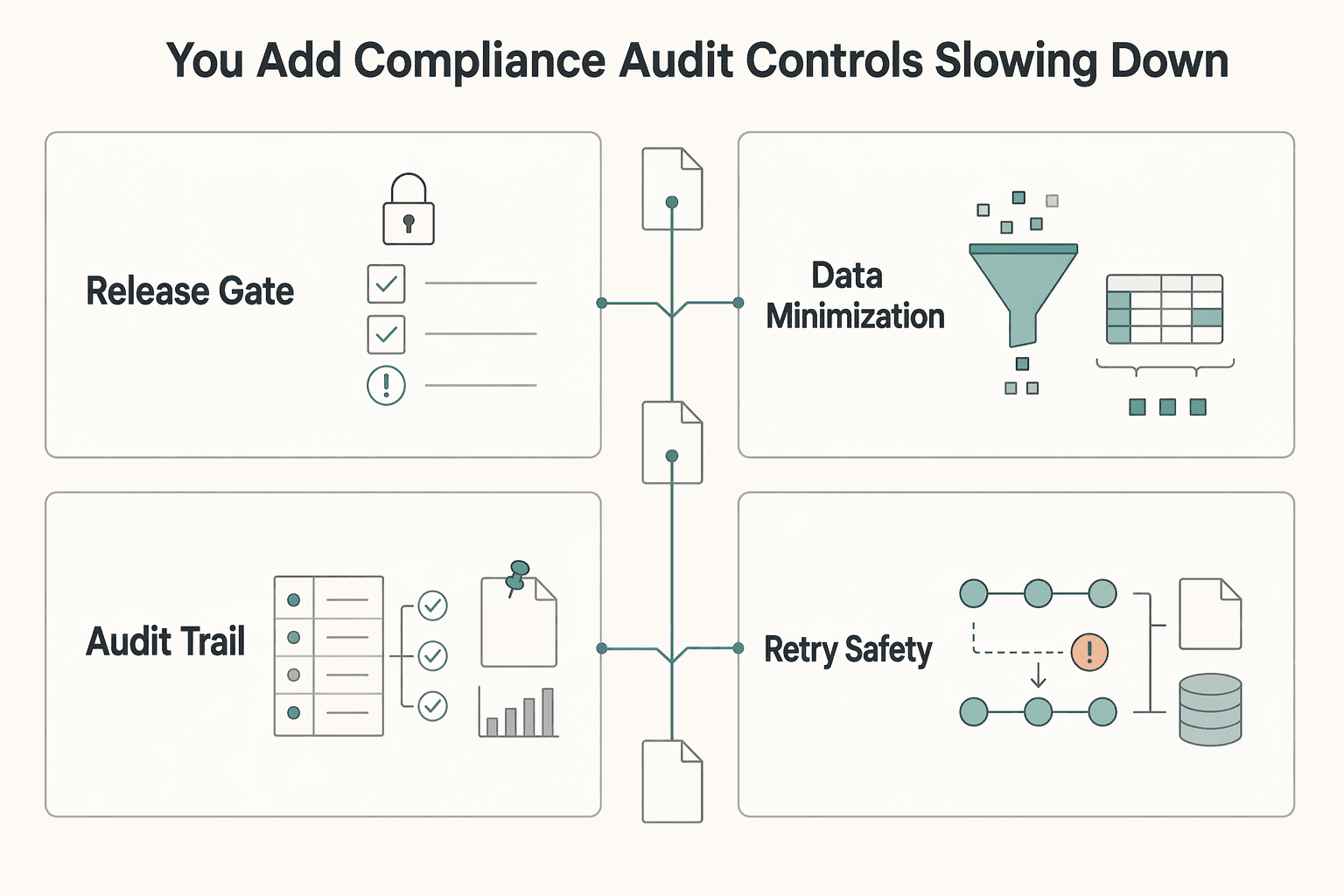
| Control layer | Apply it at this workflow moment | Owner | Verification signal |
|---|---|---|---|
| Approval gate | Immediately before a client-facing status change, invoice send, payout-related action, or tax-relevant edit | Named approver for that workflow | A test event reaches the review step, and the downstream action does not proceed until approve/reject is resolved |
| Data minimization | When mapping trigger fields into downstream actions | Zap owner | Only required fields are mapped for the next step; extra personal or payment detail is not passed through |
| Audit trail | After each high-impact run, and after connector/account setting changes outside the Zap | Zap owner plus app admin (where relevant) | You can reconstruct one event end to end using run history, change log (where available), and one exception note |
| Retry safety | Any finance-sensitive create/update/posting action | Finance owner or automation owner | Replaying the same event produces one matched record path, not duplicate financial records |
Put approval where impact is highest#
Use approval only where the decision has real business impact. A step such as Request Approval belongs before actions that move money, finalize client state, or send external final communications, not on low-risk intake tagging or internal filing.
| Action type | Approval placement |
|---|---|
| Client-facing status change | Immediately before the change |
| Invoice send | Immediately before send |
| Payout-related action | Immediately before the action |
| Tax-relevant edit | Immediately before the edit |
| Low-risk intake tagging | Do not place approval here |
| Internal filing | Do not place approval here |
Keep the control boundary clear: platform safeguards can help with infrastructure-level monitoring and retries, but your operating procedure decides whether a high-impact action is authorized. If you cannot identify who approved a money-related action, the control is not reliable.
Minimize data and keep a usable evidence loop#
Triggers can come from webhooks, APIs, or polling, and payloads often include more than you need. Pass only the fields required for the next action.
For high-risk flows, keep a compact evidence loop:
- Zap run history
- account/app change log where available
- short exception note when manual correction was needed
- periodic checkpoint to review recent high-impact runs
This loop supports incident reconstruction, even though it is not a substitute for legal or regulatory requirements. If useful, keep exception notes in your existing operating log, such as a Decision Journal.
Make retries and replays duplicate-safe for finance#
For finance-sensitive steps, design retries as replays, not second creates. Use stable references, for example invoice number, client ID, payment reference, or stored external action ID. Prefer lookup-and-update patterns over blind creation, and route missing or ambiguous matches to exception review.
This helps prevent the common breakdown where you fall back to manual Slack/email updates and follow-up happens late. Your target state is clear reconciliation of who was paid, when, and why. For manual replay policy, document the exact cutoff only after verifying it from workflow records, platform behavior, logs, or approved operating rules.
With these controls in place, the next step is incident recovery: how to triage broken Zaps and restore flow without creating new errors.
How Do You Handle Broken Zaps and Recover Fast#
Handle broken Zaps by classifying business impact first, containing the affected workflow, and recovering in a replay-safe order that avoids duplicate records.
| Severity | Trigger signal | What you pause | Manual fallback | Recovery owner | Incident closed when |
|---|---|---|---|---|---|
| Low | Internal filing or tagging failed, but no client sees it | Only the affected Zap path | Update the record manually and log the exception | Zap owner | The missed record is fixed and one controlled test run passes |
| Medium | A client update failed or contract status is out of sync | The affected client-facing automation | Send the update manually and correct the status | Owner plus approver | Client-facing status matches the source record and a retest stays aligned |
| High | Invoice creation, payment posting, or reconciliation is wrong or missing | The affected finance automation | Hold send/posting, then reconcile manually | Owner plus finance lead | No duplicate record exists, balances match, and a controlled retest succeeds |
Step 1: Classify impact first. Separate internal misses from client-facing mismatches and finance-impact incidents. Assign one accountable owner and record the business consequence in your exceptions log.
Step 2: Contain the affected workflow. Isolate the trigger, connection, or action that failed, and keep unrelated workflows running. Use a manual fallback so client work does not stall.
Step 3: Recover in replay-safe order. Before replaying anything, confirm how your current app pair handles retries or resubmits. For money or signed-status data, verify a stable reference, for example invoice number, payment reference, or contract ID, and stop for manual reconciliation if references are missing or conflicting.
Step 4: Run dual alerts and a weekly pattern review. Route alerts to a primary owner and a backup person or channel for high-impact automations. Track each exception, including time, apps, impact, fix, and prevention task, then review weekly so repeat failures become prevention backlog items.
Common Mistakes That Make Freelancer Automations Fragile#
Your system gets fragile when you treat automation like a one-time build instead of a system you maintain. The highest-risk patterns are weak ownership, no approval checkpoints for visible actions, and changes nobody can safely audit.
| Fragile pattern | Failure mode | Safer default | Decision cue |
|---|---|---|---|
| One-person, undocumented setup | You create a black box process with high bus-factor risk | Assign one owner and one backup, and log every production change | If only one person can explain trigger, action, and fallback, stop adding complexity until documented |
| Client-visible publishing with no checkpoint | Incorrect or poorly timed output can go live without review | Route to a draft queue, add human review, and require named publish authority | If it is public or client-visible, do not allow direct auto-publish |
| Two systems editing the same live record | Records drift and sync conflicts create cleanup work | Use one system as authority per record type; mirror others for visibility only | If both tools can edit the same invoice, client record, or status, redesign before scaling |
| Template copied straight to production | Hidden assumptions break fields, approvals, or fallback behavior | Treat templates as drafts and run a pre-production checklist | If you have not validated mapping, approvals, retries, and fallback, it is not production-ready |
| Troubleshooting everything yourself | Time loss and repeat failures from deeper architecture issues | Handle isolated issues in-house; escalate repeated or multi-app failures earlier | If it spans multiple apps, auth, retries, or undocumented logic, escalate |
-
Set ownership before adding more automations. Fast, build-now habits often create debt that shows up later, including costly rewrites. Your minimum standard: a second person can explain the flow and the change process without guessing.
-
Put a human checkpoint before anything public. Keep client-visible publishing in a review queue and require explicit release approval. Test the full path with a non-production example before you trust it live.
-
Enforce one authority per record type. Keep mirrors read-only for visibility, not parallel editing. When conflicts appear, reconcile first, then replay steps.
-
Escalate by complexity, and validate every template before go-live. Use in-house troubleshooting for contained issues; escalate when failures are repeated, cross-app, or black-box. For template-derived flows, require pre-production checks for field mapping, approval points, retry behavior, for example wait 30 seconds and retry, manual fallback, and one end-to-end test record.
Run the One Afternoon Go Live Checklist#
Go live in one afternoon only if each flow is clear to run, easy to monitor, and recoverable without guesswork.
- Block the afternoon and freeze scope first. Put each task on your calendar so work time is defined, not assumed open. Keep today limited to intake, contract, payment, and bookkeeping sync, and write two lists before publishing anything: in scope today and out of scope today. Move anything with untested approvals, custom logic, or client-facing judgment to out of scope.
Check: for each in-scope flow, you can name the owner, source app, destination app, and manual fallback.
- Use a go-live gate for every flow. If ownership is unclear, monitoring is weak, fallback is missing, or recovery is vague, defer it.
| Flow | Go live now | Defer |
|---|---|---|
| Intake | Owner is clear, new records are easy to spot, and one missed record can be re-entered manually | Fields change often, routing is unclear, or misses are hard to detect |
| Contract | Status changes are visible and a manual check happens before client-facing actions | Downstream actions are hard to undo if status is wrong |
| Payment | You can verify each record against one source of truth and correct one safely | Errors could create duplicates, wrong reminders, or client confusion |
| Bookkeeping sync | You can reconcile transferred records and replay one item safely | Mapping is still changing or duplicate handling is unclear |
-
Classify fields before publishing. Mark each field as required, sensitive, or optional. Keep required fields only when the next step needs them; review sensitive fields before passing; remove optional fields unless there is a clear use. For retention, do not publish a placeholder rule. Document the current rule only after jurisdiction review and approved operating rules confirm what applies.
-
Define failure, rollback, and escalation in plain language. Do not publish a fixed pause count until it has been verified from workflow records, platform behavior, logs, or approved operating rules. Until then, treat repeated failed runs, duplicate creation, or unreconciled records as review triggers, and record who can approve rollback or escalation before the flow goes live.
Check: you can run one sample, one failure, and one replay safely.
- Pilot before scale. Start with a small batch and expand only if alerting works, replay is safe, and reconciliation is clean. If bad records are not caught quickly or cleanup costs more than the admin time saved, hold rollout and fix reliability first.
Related reading: How to Use Airtable Automations to Simplify Your Agency Workflow.
Frequently Asked Questions
How do you use zapier for freelancers without adding operational risk?
Keep each Zap small enough to explain quickly, and give it one owner, one backup, and one manual fallback. Run one test record end to end, then check the trigger data, the action output, and the task history before you trust it with live client work. If you cannot show where it fails and what you will do next, it is not ready.
What should stay manual even after you automate?
Keep final approval manual when the action affects client trust, money movement, legal exposure, or public publishing. A quick judgment rule helps: automate repeatable data passing, reminders, and draft creation; keep human review for scope changes, payment exceptions, client-facing messages, and anything hard to reverse. If a wrong action would force apology, refund, or cleanup, do not let it run unattended.
What are good starter automations for a solo freelancer?
Start where you repeat the same coordination steps every week: scoping client work, keeping track of talent details, and matching projects to the right freelancer. A practical checkpoint is whether each step has one clear source of truth and one easy test record. Finance is often worth doing early because admin time has a direct cost. One freelancer example cited spending a minimum of 10 hours a week on expense tracking and similar tasks before automating. If that is your pain point, this follow-up guide on automating freelance finances is the right next step.
Should you build it yourself or hire help?
Build it yourself when the process is straightforward, low risk, and you can maintain it after the first build. Get outside help when the logic spans several apps, touches sensitive client data, or nobody can explain the current setup without digging through task history. If you are unsure, test one important process first and decide based on the cleanup it creates, not the demo that sold you on it. | Situation | Build it yourself | Get outside help | | --- | --- | --- | | One app triggers one action, and you can test it with a sample record | Yes | No | | Client-facing, finance-related, or multi-step with approvals and fallbacks | Maybe, only if you can document and maintain it | Yes | | Inherited setup with repeated errors, missing ownership, or unclear field mapping | No | Yes |
What if you do not know whether a setup is possible?
Use Zapier Community before you guess. The How Do I forum is explicitly for questions about how to do something, whether it is possible, or where to start, and it has a large archive of past topics. If the answer still points to custom design work, use the listed Hire an Expert route instead of forcing a brittle build.
What do you do when a Zap breaks during active client work?
Contain the impact first. Pause only the affected Zap, switch to your manual fallback, and record which records may need manual correction or cleanup. Your checkpoint is a small recovery batch, not a full restart. Verify the output on one or two records before you reopen the flow. Avoid rushing a fix that creates duplicate invoices, duplicate tasks, or confused client updates.
What compliance and privacy basics matter most?
Move only the fields the next tool actually needs, and document where client and payment data lands. A practical documentation set can include a data map, a short access list, and a note of which Zaps touch client information or finance records. If you cannot explain why a field is being passed, remove it.
How do you track ROI without made-up benchmarks?
Measure your own before-and-after admin time, missed handoffs, and rework, then review that regularly. The clearest signal is not a vanity number. It is whether you are spending fewer hours on coordination and keeping income, expenses, invoices, and payments in one place with fewer misses during busy months. If a Zap saves time but creates cleanup every week, count the cleanup too.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 8 external sources outside the trusted-domain allowlist.
- ciphernutz.com/blog/common-automation-developer-hiring-mist...external
- community.zapier.com/how-do-i-3/question-about-becoming-a-certifi...external
- community.zapier.com/show-tell-5/tips-on-hiring-a-certified-zapie...external
- consultevo.com/zapier-freelancer-automation-guideexternal
- f3fundit.com/make-vs-zapier-vs-n8n-ai-automation-2026external
- hastewire.com/blog/understanding-zapier-for-backend-automa...external
- news.ycombinator.com/itemexternal
- syntora.io/solutions/when-should-you-hire-an-automation...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

Automating Freelance Finances Without Losing Cashflow Control
You can [automate freelance finances](https://solofinancehub.com/blog/how-to-automate-freelance-finances) and still keep control over key cash decisions. The practical target is simple: automate repetitive admin, then keep human approval for higher-risk exceptions.

Automating Your Freelance Finances: A Zapier Workflow for Connecting Stripe, QuickBooks, and Wise
Cleaner books and fewer month-end fire drills come from sequence, not software. Run this in the right order: structure, compliance, accounting architecture, then automation.

How to Create a Signature Talk for Your Freelance Expertise
A signature talk can be a reusable business asset, not a one-off performance. Keep one core argument stable, then adapt examples, pacing, and the close for the room in front of you.