
Quick Answer
Start with a weekly reset that maps true capacity, then run each day from a written priority matrix instead of your inbox. To manage multiple freelance projects without burnout, schedule separate blocks for delivery, communication, and admin, and keep one current client hub with scope, blockers, and next actions. Escalate deadline conflicts early with written options, and close each day by logging tomorrow’s first task so execution starts cleanly.
Why managing multiple freelance projects feels chaotic even when you are good at your work#
Step 1 Diagnose the real problem#
If this feels hard, the issue is often not your craft. It is a lack of operating control: too many open commitments, a calendar filled with delivery blocks, an inbox setting priorities, and tasks that feel urgent because no clear next action exists.
| Condition | What it means |
|---|---|
| Project due dates are not visible in one master calendar | You do not actually know your load |
| Recurring admin work is not scheduled there too | You do not actually know your load |
| You are guessing from memory | Every new client adds mental load even when the hours look available |
This quick self-check tells you a lot. If your project due dates are not visible in one master calendar, and recurring admin work is not scheduled there too, you do not actually know your load. You are guessing from memory, and every new client adds mental load even when the hours look available.
Step 2 See the two clocks you are trying to run#
Your week runs on two clocks. One is delivery work. The other is business maintenance: invoicing, proposals, file cleanup, follow-ups, bookkeeping, and client coordination. If you only schedule delivery, the second clock does not disappear. It becomes a deadline problem later.
That is where calendar overload starts to feel personal. You may be good at the work itself, but if business-maintenance tasks are left to scraps of time, they spill into evenings, delay replies, and break your focus when you should be producing.
Step 3 Trace the failure chain before you accept more work#
The failure chain often looks the same: you over-accept, priorities thrash, deadlines collide, communication gets rushed, and quality starts to drift. Time-blocking helps, but it works best when you are blocking from a real view of total capacity, not hope.
The fix is a simple operating model: intake gate, capacity map, execution rhythm, communication protocol. Before you say yes to another project, verify workload visibility, ownership, and scheduling reality.
For a step-by-step walkthrough, see A guide to using Notion 'Databases' for freelance project management.
What to prepare before you accept another project#
Before you accept another project, run a short intake gate. If delivery visibility, real capacity, or dependency risk is unclear, pause the yes.
Step 1 Build one project record you will actually use#
Keep one source of truth for active work and new requests. A visual project management tool, simple database, or spreadsheet is fine, as long as details are not split across email, chat, and memory.
Use the same fields every time: scope, due date, next action, owner, blocker, and communication channel. This is a practical operating format, not a universal standard. If a request does not have a due date and one clear next action, keep it unaccepted.
Step 2 Check your calendar against actual focus capacity#
Check capacity from your calendar and task list together, not from optimism. Every active deliverable should have scheduled work time, not only a due date.
Run a 15-minute weekly scan for likely problems: stacked deadlines, work with no next action, and admin tasks with no time block. If your day is fragmented, treat that as lower real capacity. After interruptions, it can take up to 23 minutes to refocus, so a small gap between meetings may not be usable deep-work time.
Step 3 Make the tradeoff explicit#
Use an explicit decision instead of stretching by default.
| Decision | Use it when | What it protects |
|---|---|---|
| Accept now | Scope is clear, due date fits scheduled hours, and no major blocker is open | On-time, quality delivery |
| Defer | Work is a fit, but your realistic start window is later or key inputs are still missing | Quality and clear expectations |
| Decline | Taking it would crowd current commitments or force rushed work | Delivery reliability and client trust |
Step 4 Send a qualified yes, then run one final risk check#
Clients do not see your hidden workload. They judge what you promise.
| Risk item | If unresolved | Action |
|---|---|---|
| Timeline | It is fragile | Move to defer |
| Approvals | They are unresolved | Move to defer |
| Files | They are unresolved | Move to defer |
| Decisions | They are unresolved | Move to defer |
Before final commitment, send a clear response with three parts: your current load, your realistic start window, and what must be confirmed before kickoff. Example: "I can take this on. With my current load, I can start Thursday and deliver the first milestone early next week, once the final brief and source files are confirmed."
Then do one last verification pass. If the timeline is fragile or depends on unresolved approvals, files, or decisions, move to defer. That pause keeps a new commitment from turning into a recovery project. Related reading: How to Manage a Remote Team of Subcontractors.
Set your weekly capacity plan before you promise deadlines#
Map your week before you promise anything new. Once two or three projects overlap, you are managing tradeoffs, and clients judge you on what you committed, not on your hidden workload.
Step 1 Run a fifteen-minute planning session. Put it on your calendar for Monday morning or Friday afternoon, open your task list next to your calendar, and sort active work into three buckets:
- must-deliver this week
- movable items that can slide
- dependency-bound items waiting on someone else
For each dependency-bound item, write the blocker and the owner. Keep it specific so you can act on it. Do not finish this step until every active item has one next action and every dependency has a named owner.
Step 2 Build capacity from blocks, not optimism. Start with the hours you can actually work, then split them into available work blocks, protected admin blocks, and contingency buffer. Admin work includes proposals, invoices, follow-ups, revision tracking, and file cleanup, so do not treat that time as delivery capacity.
Then place committed work into those blocks. If a committed task has no calendar block, it is not planned. Protect single-tasking where you can to avoid quality loss from constant switching. For example, an eight-hour day might be a four-and-four split, or a six-and-two split when one task is heavier.
Step 3 Check dependencies before you confirm dates. A due date is reliable only when required inputs are visible. If approvals, files, or stakeholder responses are still unclear, do not lock the final timeline yet. Send a qualified commitment: what you can start now, what is missing, and when you can confirm the date after that input arrives.
Use this point to choose accept, defer, or renegotiate. Accept when work fits mapped blocks. Defer when the fit is good but timing is not. Renegotiate when scope is possible but the original date is not. For every promised date, set a fallback path in case a dependency slips.
Step 4 Run a midweek correction check. Treat this as required, not optional. Compare plan versus actual progress, flag overrun blocks, and catch collisions before deadlines compete for the same hours. If the week is drifting, reset scope or timing early while clients still have room to adjust.
Your quick verification checklist: every committed task has a calendar block, every dependency has an owner, and every promised date has a fallback path.
Build a priority matrix that decides today's work in ten minutes#
Start each day by ranking work before you open the inbox: use the Eisenhower Matrix (urgent vs. important) so you choose deliberately instead of reacting.
Step 1: Capture and tag all open items. Put today's tasks in one list, then tag each for delivery impact and time sensitivity. That gives you the matrix's 4 quadrants and makes tradeoffs visible. For each item, write one next action and note any blocker or dependency owner.
| Task type | Classification | Triggered action |
|---|---|---|
| Deadline deliverable due soon | Urgent and important | Put it in your first focus block |
| Approval request blocking later work | Urgent and important | Send or chase it early to unblock downstream work |
| Admin follow-up with no same-day consequence | Important, not urgent | Batch it into an admin block later today |
| Revision request | Depends on promised date and sign-off risk | Schedule an edit block, or reset timing if it displaces committed delivery |
Step 2: Break ties with one consistent rule set. When two items land in the same quadrant, decide in this order: dependency unblock, client impact if delayed, then rework risk if postponed. Keeping one rule set prevents tie decisions from stalling.
Step 3: Build a realistic today list. Anchor it to your first focus block, not your wish list. If a new request comes in, capture it and defer judgment to your next checkpoint unless it clearly outranks the top item. If you must re-prioritize, move the lowest-impact unblocked task, not everything.
Step 4: Re-rank at checkpoints, not continuously. Reset priorities when a blocker appears, an approval slips, or a new dependency changes execution order. This protects you from the urgency trap, where loud threads displace important work and carryover keeps repeating. If carryover persists for several days, reduce scope early.
Turn your plan into a daily execution routine you can sustain#
Use a simple reset -> execute -> close cycle every day so overlapping timelines do not decide your priorities for you. You are not aiming for perfect control; you are making sure each active project gets the attention it needs, even when communication gets noisy.
- Reset before you open the inbox. Do a short checklist: align your ranked list with today's calendar blocks, account for overnight changes, and clean up carryovers so each open item has one next action. Then define your first deep-work move as a clear deliverable (for example, "finish revision notes for Client B deck," not "work on presentation").
Verify: your top-ranked item is in your first focus block, and blockers or dependencies are visible before you start.
- Execute by protecting focus and containing replies. Start with the highest-impact task, not email, chat, or low-risk admin. Use planned client reply windows so people still hear from you without breaking production all day. Re-rank only when new information changes a promised date, creates a blocker, or clearly outranks what you are doing; otherwise capture it and review at your next checkpoint.
Keep one practical rule: do not drift into personal projects or tidy-work until critical client work is done or clearly underway. When due dates compress, choose one project to lead and defer the other on purpose.
| Day or task pattern | Use this approach | Avoid this mistake |
|---|---|---|
| Shallow admin work | Batch invoices, follow-ups, approvals, and file cleanup into one contained block | Sprinkling admin between delivery tasks and losing momentum |
| Deep delivery work | Protect an uninterrupted block for drafting, analysis, or complex revisions | Letting chat and inbox checks split one hard task into repeated partial starts |
| Interruption-heavy day | Lower daily scope, keep one must-finish item, and move noncritical work to a later block | Treating it like a normal production day and carrying everything over |
- Close with tomorrow's handoff note. Before shutdown, capture five fields for each active project: progress, blockers, dependencies, decision owner, and next action. If you are waiting on a file, approval, payment confirmation, or a client answer, name it directly and assign who owns the next follow-up.
Verify: tomorrow's first task is already written, and your notes let you send a clear client update quickly. If carryover keeps rising or late work becomes routine, treat it as an operating risk and adjust boundaries to protect quality and consistency.
Use task batching and time blocking without going silent on clients#
Batch by work mode first, then place communication windows around those blocks. That keeps output steady without making clients feel ignored.
- Group tasks by mode on one master calendar. Keep research, drafting, revisions, approvals, and admin in separate blocks instead of mixing them all day. Similar work reduces switching, and your calendar should show both delivery work and recurring business maintenance.
Verify: each active project has a visible production block, and every client commitment from email or chat is logged in your centralized project hub.
- Put communication around production, not inside it. Plan reply windows before or after focused work so clients still get clear visibility. Use this response framework:
- Acknowledge quickly: new requests and decisions received. * Hold for next window: non-urgent questions that do not change today's plan. * Escalate immediately: anything that creates a blocker, changes scope, or puts a promised date at risk.
If you keep replying inside drafting time, your production blocks get fragmented.
- Protect a separate admin batch every week. Keep invoicing, records, follow-ups, and file cleanup out of delivery blocks. When admin is not batched, it usually spills into evenings or turns into an end-cycle stack of overdue tasks.
| Day type | Block style | Communication handling | Best use |
|---|---|---|---|
| Interruption-heavy | Shorter focus blocks with planned check-ins | Review messages at each check-in and isolate blockers | Edits, approvals, follow-ups |
| Deep-focus | Longer uninterrupted production blocks | Hold routine replies for the next window | Research, drafting, complex revisions |
| Admin catch-up | One contained admin batch | Send status updates and log commitments as you go | Invoices, records, file hygiene |
Spend 5 minutes each day confirming tomorrow still includes production time and one admin touchpoint. If either keeps disappearing, delivery risk and business risk are both rising.
Set a client communication protocol that prevents fire drills#
Most fire drills start with unclear expectations, so set one communication protocol at kickoff and reuse it on every project.
Use this kickoff checklist in your project notes:
- Cadence: when updates happen.
- Update format: use one structure each time: progress, blockers, decision needed, next milestone.
- Routine response expectations: what waits for the next reply window.
- Escalation channel: where urgent issues go.
- Decision log location: where final decisions are recorded in your project system.
Pick your rhythm by how often client input can stop delivery:
| Project type | Decision dependency | Communication rhythm | What to send |
|---|---|---|---|
| Low-touch delivery | Low | Milestone-based or scheduled summaries | Progress, next milestone, open questions |
| High-feedback collaboration | High | Frequent planned check-ins | Progress, feedback needed, next review point |
| Dependency-heavy work | Medium to high | Check-ins tied to approvals or required inputs | Blockers, owner, next action, date risk |
Set escalation rules in plain language and apply them consistently:
- Routine: status questions, small clarifications, non-blocking edits -> reply in your next planned window.
- Blocker: missing assets, overdue approvals, or revision requests that affect scheduled work -> escalate through the agreed channel and follow your team target (
<routine-response-target>/<blocker-response-target>). - Immediate escalation: scope change, slipped dependency, or any risk to a promised date -> use the urgent channel now and follow your urgent target (
<urgent-response-target>).
Log every key decision in your project hub with the decision, owner, and next step. If decisions stay in chat threads or in your head, rework risk rises and you invite the forgotten-send-off, 3 AM panic version of freelance work.
Handle conflicting deadlines with escalation rules instead of panic#
When deadlines conflict, your safest move is to escalate early with written options, not improvise. Do this before a late-week "quick" request turns into Sunday 23:30 recovery work and a rushed Monday handoff.
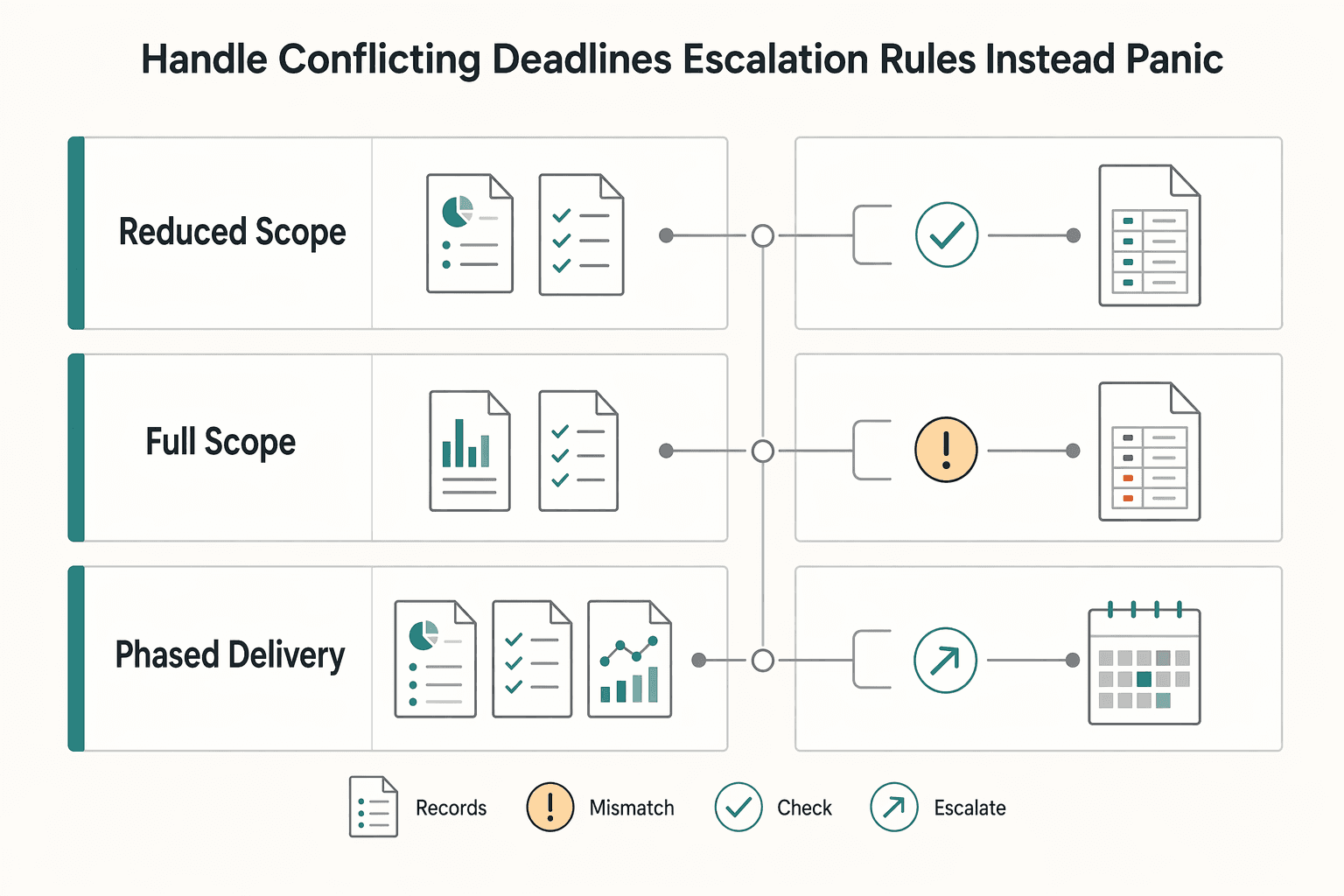
Step 1: Map the conflict before you reply. Write a short conflict brief in your project hub, not across chat threads. For each project, note: remaining work, dependency status, business-critical outcome, and what fails if the current date holds.
Do not treat both deadlines as equally urgent by default. If work depends on client files, approvals, or reviews, that dependency risk is part of the decision. Verify: each item has a named client decision owner and a next milestone that could slip.
Step 2: Present options with clear tradeoffs. Ask the client to choose from defined paths instead of sending an open-ended "what do you want to do?" message.
| Option | Business-critical outcome | Quality risk | Dependency risk | Client decision owner |
|---|---|---|---|---|
| Reduced scope on original date | Core deliverable still ships on time | Lower if trimmed items are nonessential | Lower when removed items rely on missing inputs | Client confirms what moves later |
| Full scope on revised date | Full outcome stays intact | Lower than rushing full delivery | Lower if dependencies get time to clear | Client approves revised date |
| Phased delivery | Highest-priority piece lands first | Medium if phase split affects cohesion | Medium because later phase still needs tracking | Client approves phase split and order |
Recommend one option directly. Reliability is risk control, not heroics.
Step 3: Use a simple trigger framework. Escalate immediately when a promised date is at risk, a dependency is blocked, or scope changes affect scheduled work. Use same-day planning when capacity tightened but at least one workable path remains. Keep normal monitoring when nothing slipped yet, but repeated follow-up pressure or late-week "quick" asks show the plan is getting fragile.
Do not promise "I'll squeeze it in" if that bypasses the decision record.
Step 4: Confirm the decision in writing. Send a short written summary with the chosen option, milestones, owners, and next update point. Keep planned outbound updates visible on one calendar-style outbox so follow-through is scheduled, not remembered.
Step 5: Treat repeats as a capacity signal. If this conflict pattern repeats, adjust the system: tighten your acceptance filter, revise your weekly capacity plan, and reset active-project limits. Use a brief after-action note each time: trigger, missed signal, rule change.
Protect delivery quality from scope creep and hidden admin drift#
Protect quality by running one weekly control loop: check your scope baseline, update your change log, and confirm your calendar commitments in the same sitting. That is how you catch scope leakage and admin drift before they turn into rushed delivery and margin loss.
Step 1. Reconfirm your scope baseline for each active deliverable. Keep one current scope record per project so you are not managing from old proposals, chat threads, and memory. Make sure it clearly shows what is in scope, what is out, the next milestone, and the next decision owner. If a request is vague, clarify it before work starts. Vague deliverables are where overservicing begins.
Verify: every new ask from the week is checked against the baseline and logged. If it only exists in Slack, email, or call notes, treat it as unapproved until recorded.
Step 2. Route every incoming request through one decision table. Do not decide ad hoc. Log the decision first, then act.
| Status | Choose when | Capacity impact | Delivery risk |
|---|---|---|---|
| Accept now | The ask fits the agreed deliverable and your current plan can absorb it | Low when it does not displace committed delivery or planned admin work | Low when owner, due date, and acceptance point are recorded |
| Defer | The ask is related but not required for the current milestone, or it would overload this week | Medium because work moves forward instead of stacking now | Lower than squeezing it in, if the new date is confirmed in writing |
| Price separately | The ask is outside baseline scope or adds meaningful effort (including extra revision cycles) | High because it creates net-new work not covered by the current estimate | Lower than doing unpaid extras, if you wait for written approval before starting |
Use one intake red flag consistently: if a request adds frequent real-time communication, include that admin load in the decision.
Step 3. Protect admin categories with a non-negotiable fallback rule. Block weekly time for project management, client communication, account/admin follow-through, and scope/change documentation. These tasks are part of delivery quality, not optional cleanup. Fallback rule: if an admin block gets bumped, rebook it in the next open slot that same week before adding discretionary delivery work.
Step 4. Track revisions as a separate signal. Log revisions separately from core delivery: request, scope decision (in or out), effort impact, timeline impact, and approval record. Use that record in your next estimate, pricing, and client-fit decisions. This protects margin when work starts behaving like a 20-hour plan turning into 35 hours, and it helps you spot chronic instability early.
Verify: revision volume, unpaid extras, and admin carryover are not rising together. If they are, tighten scope, raise estimates, or reset whether the engagement still fits.
Keep money and compliance work from becoming a month-end crisis#
Finance drift becomes a month-end crisis when you treat money and compliance as leftovers instead of weekly operations. Keep one fixed cadence, and require written proof before anything counts as done.
Schedule and close one fixed weekly finance block#
Run one recurring weekly block for invoice status, payment reconciliation, expense categorization, record completeness, and compliance review. Treat this like delivery work: inconsistent income flows get harder to manage when admin waits until month end.
| Completion check | Confirm |
|---|---|
| Client statuses are current | Every active client has current statuses |
| Prior-week transactions are reviewed | No prior-week transaction is still unreviewed |
| Next reserve transfer is logged | The next reserve transfer date is documented |
During that block, update five statuses for every active client: invoice sent, payment received, books updated, compliance reviewed, and advisor escalation needed. Also confirm your reserve routine. If you use a separate savings account for your safety cushion, verify the last transfer happened on schedule (for example, every quarter) and log the next transfer date.
Done when: every active client has current statuses, no prior-week transaction is still unreviewed, and the next reserve transfer date is documented.
Update each client evidence pack when events happen, not later#
Your weekly block only works if you capture facts during the week. When a payment lands, an expense posts, or a document request arrives, update that client file the same week.
Keep one evidence set per client: invoice log, payment history, expense receipts, tax documents, and account notes. Spreadsheets can show totals, but they can still create a false sense of control if notes do not explain what the payment covered, who paid it, or which requests are still open.
Use these anti-drift triggers and immediate actions:
| Early warning signal | Immediate corrective action |
|---|---|
| Missing transaction classification | Tag and classify it before you close the week |
| Unresolved payment status | Send follow-up the same day and log the promised date |
| Incomplete account notes | Rebuild notes from source email, contract, or bank record immediately |
Done when: another person can open the file and see what was billed, what was paid, what documents exist, and what remains open without asking you to reconstruct it.
Record each filing decision separately#
Do not mark compliance as one generic "reviewed" step. Record each possible filing as its own yes/no decision with facts used, documents checked, review date, and open questions.
| Decision factor | You can self-document now | Escalate to advisor now |
|---|---|---|
| Clarity of facts | Account type, owner, location, and records are clear | Ownership, classification, or values are unclear |
| Cross-border complexity | Limited, straightforward facts | Multiple countries, mixed personal/business facts, or entity layers |
| Risk of misclassification | Prior treatment is documented and facts match | A wrong label could change filing treatment or leave a filing unanswered |
Done when: each required filing has its own decision trail, and no open issue is buried in a generic "tax review" note.
Hand off advisor questions with a clean packet#
When you escalate, send one tight packet: exact question, verified facts, supporting documents, prior treatment (if any), and the decision you need back. Include any unresolved placeholder thresholds or due dates so the advisor can confirm them directly.
Then log the handoff: what you asked, what you sent, what answer came back, and what action you took. That record stops repeat fire drills next cycle.
Done when: you or an advisor can reconstruct the issue in five minutes. If this block slips two weeks in a row, cut lower-value work before backlog compounds. Once this weekly control routine is stable, use How to Manage Bookkeeping for Your Freelance Business to build the deeper bookkeeping system.
Common mistakes that break multi-project systems and how to recover#
When your week breaks, it is usually not one failure. It is a stack of small habits that quietly overload delivery, admin, and recovery. Fix the pattern this week, then stabilize your commitments.
| Mistake pattern | Early warning sign | Recovery action | Evidence it is fixed |
|---|---|---|---|
| Accepting work before checking capacity | You say yes before the work has a real place in your calendar | Run a load check before acceptance, then revise scope or timing if needed | Every accepted deliverable has a calendar block, next action, and owner |
| Letting the inbox rank your day | You keep switching clients and finish little by midday | Write a daily re-rank and change priorities only in writing | Your first focus block goes to your written top item, not the loudest message |
| Sending inconsistent client updates | Clients chase status and approvals are scattered | Use one fixed update format and one primary client record | Each client has a current written update with clear blockers and decisions |
| Letting shutdown slide into catch-up time | Evenings and weekends absorb unfinished admin and rework | Protect a shutdown boundary and log tomorrow's first action before you stop | You close the day in writing and stop carrying loose ends in your head |
What this looks like: You accept work because it seems small, income feels uncertain, or the client sounds easy. Then the hidden load shows up in follow-ups, approvals, scheduling, and invoicing. High-touch clients can intensify this because frequent communication and shifting deadlines add coordination work.
Why it breaks your system: Each client relationship adds administrative overhead beyond core production work. If you skip a load check, you stack coordination on top of delivery.
How you recover this week: Before accepting anything new, review your calendar and task list together. Confirm every active deliverable already has a real block and one next action. Classify incoming work as accept now, accept with revised timeline, or decline. If you already overcommitted, send a written reset with either reduced scope on the original date or full scope on a revised date.
Proof of recovery: No accepted project lives only in email. Each one has a block, next action, and written delivery assumption.
What this looks like: You start in chat or email, bounce across clients, and mistake activity for progress. One cited estimate puts refocus time after interruption at about 23 minutes, and switching across four clients can cost 90+ minutes in context recovery. Do not treat those numbers as universal, but do treat context-shift cost as real.
Why it breaks your system: Inbox pressure promotes urgency over commitment. That raises carryover and hides blocker risk until deadlines feel sudden.
How you recover this week: Write your top three before opening communications. Re-rank once in writing if conditions change. Use a tie-break rule you already trust, such as nearest contractual deadline or highest blocker risk. If a new request interrupts your plan, write where it lands before you work on it.
Proof of recovery: You can point to a written priority order that explains what you did and why.
What this looks like: One client gets a structured update, another gets fragmented chat replies, and approvals sit in different places. Work becomes scattered across disconnected tools and momentum drops.
Why it breaks your system: Freelance project management includes intake, communication, approvals, time tracking, and invoicing, not only task tracking. Inconsistent updates create rework, scope confusion, and status chasing.
How you recover this week: Use one repeatable update format for every active client: progress, blocker, decision needed, next milestone. Keep one primary client record where the latest update and approval live.
Proof of recovery: Every active client has a current update in the same format, and open decisions are easy to locate.
What this looks like: Evenings become catch-up time, weekends absorb admin, and days stop ending cleanly. This is boundary erosion.
Why it breaks your system: Without intentional controls, multi-client work can move toward burnout. Late-night recovery can mask overload instead of fixing it.
How you recover this week: Protect a shutdown boundary. In your final minutes, log loose ends, client blockers, and tomorrow's first action. If work still does not fit, cut lower-value tasks, move dates, or reduce active commitments.
Proof of recovery: You end the day with a written closeout and maintain your shutdown boundary on most days.
When multiple warning signs appear together, pause intake. Send a written reset to affected clients, re-baseline your capacity, and resume only after every active commitment has a block, owner, and current status. If you need a deeper reset on the time side, read How to Manage Your Time Effectively as a Freelancer.
Your copy-paste weekly checklist for managing multiple freelance projects#
Run this reset once a week in this order, with your calendar and task board open. Start from real capacity, not optimism, and end with one defined first task for the next workday so you start executing immediately.
Before Step 1, make sure your centralized client hub is current: active/inactive status, agreed pricing, invoicing terms, deadlines, current scope, and where the agreement lives. If possible, keep a standard folder structure for each new client, including an Agreements folder for contracts.
| Step | What to do | What to verify | Common failure to avoid |
|---|---|---|---|
| Step 1 | Rebuild your weekly capacity plan from actual available hours and current commitments. If you use client slots, place each request in the next available slot. | Every active deliverable has a calendar block, one next action, and one named risk or dependency. | Filling the week to full capacity and leaving no room for revisions, approvals, or urgent fixes. |
| Step 2 | Re-rank open work in your priority matrix before you open inboxes. Set a daily top three with delivery work plus one operations item. | Your first focus block is assigned to the highest-priority item, not the loudest thread. | Letting reactive messages override your ranking rules. |
| Step 3 | Protect deep-work blocks and one admin block. Keep drafting/analysis/build work separate from invoices, file hygiene, reconciliation, and follow-ups. | Delivery time and admin time are both on the calendar before the week starts. | Using admin time as overflow until billing and records pile up. |
| Step 4 | Send updates on a planned cadence using one script: progress, blocker, decision needed, next milestone. Record the next decision owner for each open item. | Each active client has a current status note, and each waiting item has an owner. | Sending vague updates that hide blockers and leave decisions unowned. |
| Step 5 | Review risks, misses, and scope changes before shutdown. Update the scope-change log and decide whether next week needs reduced scope, a date shift, or paused intake. | Every extra request is marked accepted, deferred, or repriced, and the next workday has one defined first task. | Treating repeated overruns as a motivation problem instead of adjusting load or timeline rules. |
If you handle ad hoc assignments, keep dates tied to availability and assign new work to the next open slot when capacity is full.
Finish the reset by writing your first task in plain language, like "Draft section two for Client A" or "Send revised estimate to Client C." If you want admin to stay light too, create bills quickly with the Free Invoice Generator.
Frequently Asked Questions
How do freelancers manage multiple projects without burnout?
Start with your capacity plan, not motivation or hope. Put a fifteen-minute weekly planning session on Monday morning or Friday afternoon, review upcoming tasks, and break work down by day so risks show up early instead of midweek. Warning sign: if evenings keep turning into spillover time, your load may already be above what you can sustain well.
How many freelance projects should I handle at the same time?
Set your client capacity limit from real demand, not from a guessed project count. Your limit depends on your own tolerance and how demanding each client is. Open your calendar and task board, then confirm that every active deliverable already has a block and a clear next action. Client demands can create heavy overhead even when client count looks manageable. Warning sign: if one more request would create unblocked work, accept only with a revised timeline or decline.
What is the best way to prioritize tasks across clients?
Rank your work before you open email or chat. Look at the whole workload, weigh needs and deadlines together, then give the first focus block to the highest-priority item. Re-rank in writing when conditions change so the plan stays visible. Warning sign: if the loudest client keeps deciding your day, your inbox is outranking your priorities.
How do I handle two clients asking for same-day delivery?
Pause and map the conflict before you promise anything. Review both requests against your full workload, including remaining work and dependencies, then prioritize by needs and deadlines. If both cannot be delivered well on time, communicate a revised timeline or phased delivery instead of overcommitting. Warning sign: if you tell both clients “I’ll try,” you have hidden the risk instead of managing it.
Should I use time blocking or the Pomodoro Technique?
Both protected time blocks and theme blocking help reduce context switching across projects. A practical setup is one deep-work block (for example, 9 AM to noon) and separate blocks for revisions or admin. Warning sign: if you feel mental whiplash from constant switching, your day is too fragmented for the work you are doing.
How do I stay organized with project work, invoicing, and admin?
Keep one current view so important work does not disappear across separate tools or calendars. Use a Kanban-style board with clear status columns, including waiting states such as Incoming and Waiting for Client Assets, and review it during your weekly planning session. Keep admin tasks visible in that same weekly workflow so they are not managed in isolation. Warning sign: if you cannot quickly answer what is blocked, your records are too scattered.
What should I do when scope creep keeps blowing up my week?
Treat every extra request as a capacity and prioritization decision before you start the work. Check whether it fits your current workload and deadlines; if it does not, defer it or renegotiate timeline or scope. Taking on one too many projects or requests can make all work suffer and increase burnout risk. Warning sign: if “small” extras keep arriving while planned work slips, your capacity boundary is not being enforced.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- dhs.ri.gov/media/7311/downloadtrusted
- hbs.edu/managing-the-future-of-work/Documents/Buildi...trusted
- my.chatham.edu/documents/getfile.cfmtrusted
- pmc.ncbi.nlm.nih.gov/articles/PMC9754259trusted
- scholarworks.sjsu.edu/cgi/viewcontent.cgitrusted
- 6figurecreative.com/how-to-create-an-external-brain-that-helps-y...external
- askamanager.org/2021/03/my-job-focuses-on-my-biggest-weaknes...external
- birdviewpsa.com/resource-management-guide/faq/how-allocate-r...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

Freelance Bookkeeping for Faster, Safer Client Payments
Control over cash starts with records you trust. When entries are current, categorized, and easy to trace, you spot risk earlier and make calmer decisions about follow-up, spending, and month close.

How Remote Professionals Stay Healthy During Long Stays Abroad
Use this sequence before workload, housing, and travel friction make health tasks harder to execute. If you are traveling for months, treat this as four pass-fail gates. A gate is closed only when you have a written output you can verify.

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.