
Quick Answer
Handle a micromanaging client by treating the behavior as a delivery risk, not a personality problem. Log interruptions for one week, measure time and delayed deliverables, then redirect work into the agreed SOW, feedback channel, approval owner, update cadence, and written change process. Use outcome-based updates and short redirects instead of constant ad hoc replies.
Beyond Annoyance: The P&L Case Against Micromanagement#
Treat a client micromanaging project as an operating risk first, not a personality problem. Before you debate tone or intent, measure what the interruptions are doing to delivery time, focus, and team capacity. If you do not track them, you can keep absorbing them as "just part of client service" even when they are quietly reducing the value of the engagement.
Step 1. Start by logging the overhead#
Start with one week of simple tracking. You are not trying to prove bad intent. You are separating normal delivery work from non-billable interruption work so you can see the pattern clearly.
Use a lightweight evidence log for each interruption: date, channel, who initiated it, what was requested, minutes used, and what planned task got displaced. That last field matters. A ten-minute message is rarely just ten minutes. It can also break deep work, force re-explaining, or create conflicting feedback.
| Work area | Normal delivery work | Micromanagement overhead | What to verify | Your field to fill |
|---|---|---|---|---|
| Status communication | Scheduled update tied to milestone or agreed check-in | Extra "just checking" pings asking for reassurance without a new decision | Count unscheduled messages and total minutes spent replying | ___ messages / ___ hours |
| Feedback | Consolidated comments in one place | Drive-by comments across chat, email, and calls that force reconciliation | Note how many channels carried feedback on the same item | ___ channels / ___ rework hours |
| Approvals | Clear signoff from the decision-maker | Reopened approvals, extra reviewers, or the same item being re-litigated | Track how often approved work returns without new scope | ___ approval reversals |
| Execution time | Planned build, design, writing, analysis | Re-explaining approach, context switching, duplicate reporting | Record which deliverable slipped because of the interruption | ___ task delayed |
After five business days, you should be able to point to three facts: how often the interruptions happened, how much verified time they took, and which deliverable moved because of them. If you want a rough P&L view for your own file, compare those verified hours against the capacity or fee you expected to protect. Keep that as planning math for this engagement, not a universal benchmark.
Step 2. Read the signal without rewarding escalation#
More oversight can signal that the client feels uncertain, exposed, or pressured on their side. That does not automatically mean they doubt your skill, and it does not mean you should over-service them with constant access. In practice, the read is simpler: they may be asking for confidence, but in a costly way.
Your response pattern matters. If you answer every interruption with more ad hoc updates, you can teach them that anxiety gets rewarded with immediate access. If you go cold or sound irritated, escalation can follow. Use a simple checkpoint: once people are complaining upward about your visible disengagement, the problem is already bigger than the original request.
The lower-friction move is to acknowledge the concern, answer the decision behind it, and restate the next checkpoint. You do not need to perform exaggerated enthusiasm. You do need to avoid obvious resistance and show up graciously. If the client asks, "Can you send updates as you go?" a stronger reply is, "Yes, I will send the next progress note at 3 p.m. with the open decision and what is blocked," not "Sure, I will keep you posted all day."
Step 3. Choose the partner posture on purpose#
This is where the vendor-versus-partner difference becomes real. A top-down "do as I say" exchange can invite more control dynamics on both sides. A steadier posture is to act like the responsible operator: you keep the client informed, but you also direct the channel, timing, and decision path.
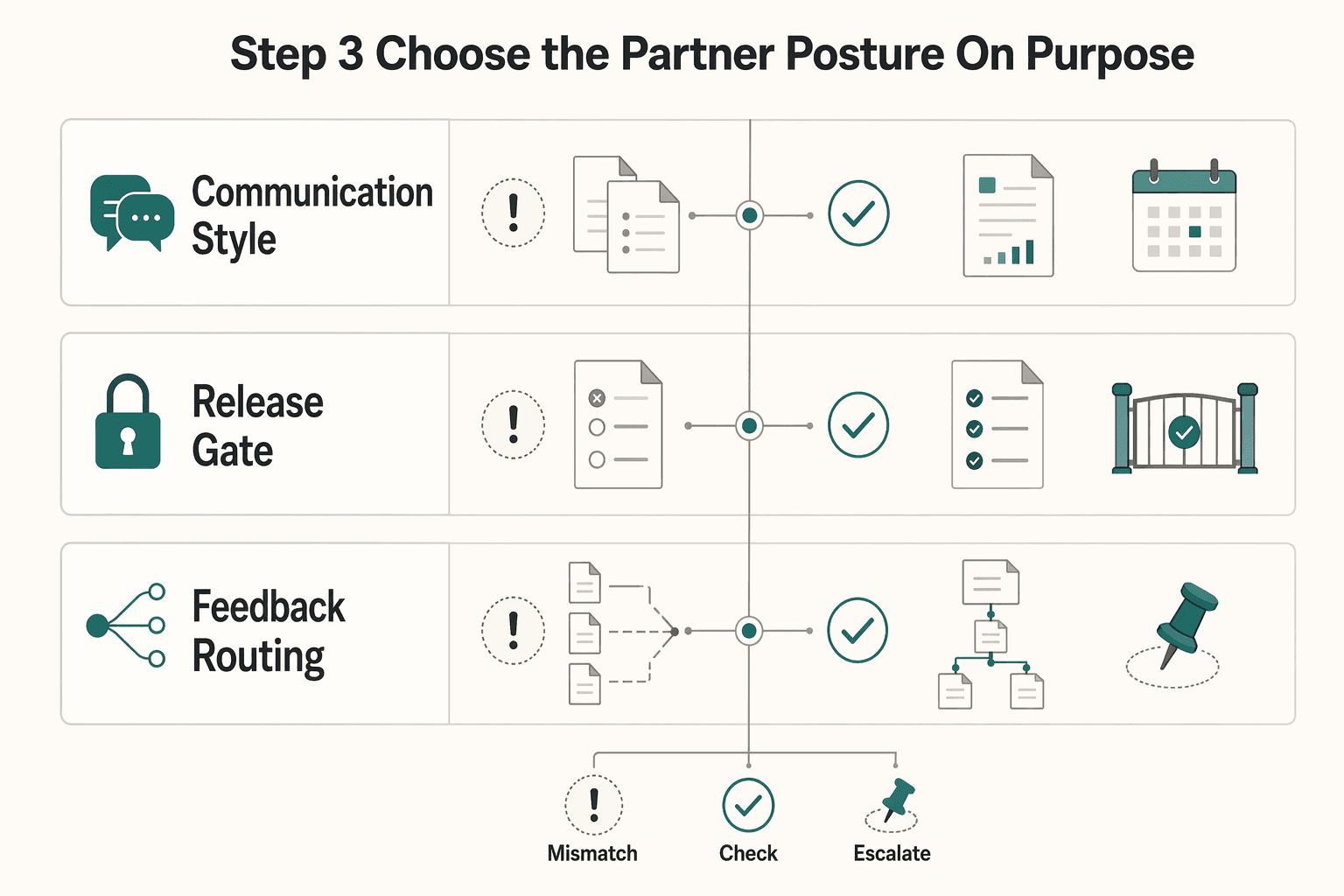
| Area | More reactive | More controlled |
|---|---|---|
| Communication style | Reacting to every ping | Answering with the next concrete checkpoint |
| Approval flow | Taking approval from whoever appears in the thread | Confirming who is actually deciding |
| Feedback routing | Accepting comments anywhere | Asking for one place where feedback is consolidated and reviewable |
Use this checklist against your current habits:
- Communication style: Are you reacting to every ping, or answering with the next concrete checkpoint?
- Approval flow: Are you taking approval from whoever appears in the thread, or confirming who is actually deciding?
- Feedback routing: Are you accepting comments anywhere, or asking for one place where feedback is consolidated and reviewable?
One tradeoff is worth stating plainly. Complex work can remain hard, unpredictable, and somewhat stressful. The point is not to create a friction-free project. It is to cut the avoidable overhead that turns normal pressure into delivery risk.
Once you can show where the time is going and how the escalation pattern works, the next move is to put those controls into the engagement itself. You might also find this useful: How to Handle a Client Who Constantly Delays Providing Feedback.
The Proactive Shield: How to Contractually Fortify Your Engagement#
Move this upstream: your SOW should be the operating document that defines how work, feedback, and approvals run before pressure builds. If those rules stay vague, day-to-day decisions default to personality instead of process.
Step 1. Define project-specific roles before kickoff#
Before kickoff, do a quick role-mapping pass for this engagement instead of relying on generic language alone. Write down who approves, who consolidates comments, where feedback is submitted, what counts as acceptance, and what triggers a scope-change review.
| Control | What to define |
|---|---|
| Scope boundaries | Include exclusions |
| Acceptance criteria | Tie deliverable acceptance criteria to observable outputs |
| Feedback channel | Use one place for consolidated feedback |
| Approval owner | Name one approval owner |
| Escalation path | Define an escalation path for stalled review or conflicting direction |
A simple quality check: for each major deliverable, can you point to one approval owner, one feedback channel, and one signoff path?
Step 2. Replace vague wording with observable clause language#
Clear language gives you a usable operating reference, even though exact contract mechanics still depend on your agreement and advice. Treat this as a blueprint, then verify each cadence, channel, response window, and approver from contract or client records before use:
- Status updates: Provider sends updates on the cadence verified in contract or source records via the channel verified in client records; each update includes completed work, next step, blockers, and decisions needed.
- Client response handling: Client submits questions through the channel verified in client records; provider response window must be verified from the contract or policy record before use.
- Approval handling: Final approval owner must be verified from client records; target turnaround must be verified from contract or source records; other comments route through that approver or designated contact.
| Topic | Unclear wording | Operational wording |
|---|---|---|
| SPOC | "Feedback as needed." | "One consolidated feedback set is submitted via the verified feedback channel by the verified approval owner or role; other comments are treated as input until consolidated." |
| Revision handling | "Revisions included." | "Included revisions apply to listed deliverables and one consolidated review cycle; reopened approvals are reviewed as scope-change requests." |
| Out-of-scope requests | "Extra work may cost more." | "Requests outside listed deliverables/assumptions are logged, impact-assessed, and started only after written authorization." |
Step 3. Use one change-order sequence every time#
Run the same sequence every time so decisions are documented and repeatable:
| Step | Action | Key detail |
|---|---|---|
| 1 | Log the request | Date, requester, deliverable, requested change |
| 2 | Assess impact | Scope, timing, dependencies, reopened approvals |
| 3 | Send written authorization language | What changes, what stays unchanged, what decision is needed |
| 4 | Start work only after the written trigger you defined | Work starts only after the written trigger you defined |
If you skip step 3 or 4, that is usually where avoidable disputes start.
Introduce these terms in the proposal, then restate them in onboarding as delivery structure, not distrust. You are setting visibility and decision flow early so the project stays stable when stress increases.
Once this is in place, execution gets easier.
The CEO's Playbook: How to Lead a Client Back on Track#
Once your SOW sets the structure, your job is to run it consistently. When micromanaging behavior shows up, do not debate style. Redirect to the agreed controls: one approval owner, one feedback channel, defined review points, and written change handling.
Step 1. Lead with outcomes, not activity. If your update sounds like a task log, clients may ask for more day-to-day visibility. Make each update answer three things: what moved, why it matters, and what decision is next.
| Update style | Client interpretation | Likely risk | Better alternative phrasing |
|---|---|---|---|
| "I finished the homepage draft and cleaned up the files." | "What changed for the project?" | Ad hoc check-ins to inspect details | "The homepage draft is ready for the planned review point. It reflects the approved messaging and keeps the launch sequence on track." |
| "I'm waiting on feedback before I continue." | "Work is stalled; I need to step in." | Client starts directing day-to-day work | "Next step is review through the agreed channel. Once consolidated feedback is in, I can move into revisions without rework." |
| "I made the changes from everyone's comments." | "Anyone can direct the work." | Conflicting input and reopened decisions | "I applied consolidated feedback from the named approver. New comments should be routed through that approver for decision." |
Quick self-check: can they see the outcome, the active checkpoint, and the decision owner in one read?
Step 2. Use one four-part response shape across channels. In chat, email, or calls, keep your response consistent:
- Acknowledge the concern or request.
- Anchor to the agreed process (SOW/kickoff rules).
- State the next step and where it should happen.
- Confirm who owns the decision.
Channel-ready example: "Thanks for flagging this. To keep review clean, please add it to the scheduled feedback round in the shared doc. I'll assess it against the current deliverable, and final direction comes from the verified approver."
This keeps the line between useful direction and over-control clear.
Step 3. Match your response to the trigger. Use short redirects tied to existing controls:
- Unscheduled check-in: "I'll cover this in the next status update so you get the full project view, not a partial snapshot."
- Premature review request: "This is not at the review point yet. I'll bring it forward once it meets the acceptance criteria."
- Extra stakeholder input: "Helpful context. Please have the verified approver consolidate and submit one decision set."
If a request may expand work, log date, requester, channel, and affected deliverable before you act.
Step 4. Reinforce the pattern weekly. Micromanagement tends to increase when visibility feels unclear. The fix is predictable, bounded visibility, not constant live monitoring.
Weekly checklist:
- Send one outcome-based status update in the agreed channel.
- Name the current deliverable, next checkpoint, and decision owner.
- Restate open items waiting on client input.
- Route stray comments back to the approved feedback path.
- Log new requests before starting work.
- Mark reopened approvals or extra review rounds for scope assessment.
Run this the same way each week so your process, not pressure, drives decisions. Related: How to Set Boundaries with Clients as a Freelancer.
Conclusion: From Managed Vendor to Indispensable Leader#
Treat micromanagement as an operating risk, not a personality quirk. The day-to-day shift is straightforward: stop absorbing every interruption, and start routing work through documents, decisions, and agreed communication.
-
Diagnose the real cost. If frequent updates, revisions, or day-to-day intervention are eating time you cannot bill, the relationship may be becoming unprofitable. Use a practical checkpoint: review the last two weeks of pings, calls, and side comments. If many of them did not affect deadline, budget, or delivery risk, that can be a sign you are subsidizing noise instead of moving the work.
-
Put the engagement back inside the paperwork. The SOW, meeting notes, and your Micromanagement Log can become the operating record. If a request is not reflected there, treat it as pending until it is documented. A practical reset is to define one approval path, one update cadence, and written scope handling. A common failure mode is answering every ad hoc message in real time; over time, that can train the client to bypass the agreed process.
-
Lead communication and enforce scope calmly. Do not argue about whether the client is "too involved." Redirect to delivery: what changed, what decision is needed, and where it belongs. Watch for red flags like frequent feature requests or leadership stepping into day-to-day direction. If that continues after a written reset, ending the relationship is a valid business choice.
What to implement next: review your current SOW today, send one written reset on update cadence and feedback routing, and start logging interruptions from the next message onward. You do not need heroics here. Consistent process, applied the same way every time, can make you easier to trust and harder to derail.
Frequently Asked Questions
Quick-use responses
| Situation | Recommended response | Document it in | | --- | --- | --- | | Unscheduled check-in | Redirect to the next planned update unless the issue could affect deadline or delivery risk. Template: “Thanks for flagging this. I’ll address it in the agreed update channel on the next scheduled update date, unless it changes the verified deadline or delivery risk.” | Contract update clause, agenda, meeting notes | | Scope push disguised as “small” feedback | Pause work and assess impact before you act. Template: “This may change the deliverable, timing, or review cycle, so I’ll send the impact in writing before we proceed.” | Change log, meeting notes, approval email | | Boundary reset after side comments or drop-ins | Restate the agreed channel, not the client’s personality. For physical projects, unannounced site visits may create safety and insurance concerns. | Follow-up email, incident log, revised notes |
How do you contractually prevent this?
Use a contract update clause that states how often you will update the client and what triggers an exception update. Document the cadence in the SOW and restate any exceptions in kickoff notes.
What should you say when the client keeps checking in?
Use a short redirect, not a long script. A simple template is: “I want to keep visibility high without slowing delivery, so let’s keep this in the verified visibility channel and use the agreed exception trigger for urgent changes.” After you send it, log the date, channel, and what prompted the interruption so you can spot patterns.
How do you handle scope creep from a micromanaging client?
If a request changes the deliverable or timing, treat it as a scope decision before doing the work. Send a written impact note and wait for written approval before proceeding. Your checkpoint is simple: no work starts until the changed scope, budget, or timeline is documented.
When should you end the relationship?
If high-maintenance problems are clear early, declining the job can be a valid option. During an active project, if repeated boundary resets and documented cadence still fail and the risk stays unacceptable, ending the relationship may be necessary. Keep the evidence in your log and follow-up emails.
How do you raise the issue without accusing the client?
Do not call it micromanaging. Name the delivery risk instead: too many ad hoc inputs can slow the project. A good template is: “I get the need for visibility. To keep progress moving, let’s use the verified cadence, route feedback through the agreed channel, and reserve off-cycle updates for verified exceptions.”
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 3 external sources outside the trusted-domain allowlist.
- academia.edu/84039466/Making_Things_Happentrusted
- cs.arizona.edu/~mercer/Projects/BoggleWordstrusted
- piercecountywa.gov/DocumentCenter/View/40773/Employee-Performan...trusted
- sec.gov/divisions/corpfin/cf-noaction/14a-8/2019/asy...trusted
- snap.berkeley.edu/project/9274006trusted
- askamanager.org/2025/05/lets-talk-about-ridiculous-examples-...external
- askamanager.org/2025/02/people-complain-im-unenthusiastic-at...external
- financialsamurai.com/how-to-deal-with-a-micromanagerexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

Thailand's Long-Term Resident (LTR) Visa for Professionals
For a long stay in Thailand, the biggest avoidable risk is doing the right steps in the wrong order. Pick the LTR track first, build the evidence pack that matches it second, and verify live official checkpoints right before every submission or payment. That extra day of discipline usually saves far more time than it costs.

How to Set Boundaries with Clients as a Freelancer
If you want to set boundaries with clients without sounding rigid or reactive, stop deciding case by case in the moment. Decide once, in writing, then respond the same way every time a request hits a known trigger.

The Freelance Payment Penalty: A Modeled Audit of Platform Fees, FX Spreads, and Payout Delays
The money rarely disappears through a single, easy-to-spot fee. The real loss is stacked. A marketplace takes its commission, a processor adds a charge for international cards, a bank or payment company converts the currency at a spread, a platform holds the funds before release, and a wire sheds a little to intermediaries on the way in. Each layer looks defensible on its own, but the worker feels the combined result as a smaller deposit and a later payday.