
Quick Answer
Use a three-phase product hunt launch guide: prep, launch-day operations, and post-launch follow-through. Before publishing, lock listing assets, finalize your first comment, and confirm who handles replies, analytics, and escalation. During launch, monitor comment themes and signup friction, then route issues into one shared tracker instead of ad hoc chats. After day one, convert recurring feedback into onboarding, copy, and product updates, and only consider a relaunch when the value delivered to users has clearly changed.
Launch on Product Hunt Like an Operator Not a Gambler#
You will get more from a Product Hunt launch if you treat it as a repeatable set of decisions, not a one-day bet on rank. Judge success by qualified demand, feedback quality, and what happens next: signups, demos, onboarding fixes, and product changes you can act on.
That mindset matters because launches are not one dramatic moment. They slip when a series of small decisions stay fuzzy until the last minute. Careful planning beats impulse here. A written plan, even a lean one, improves judgment under pressure because it forces you to define ownership, assets, and what good looks like before comments and pings start flying.
| Operating choice | Gambler move | Operator move |
|---|---|---|
| Success definition | Watches rank and refreshes social proof | Tracks qualified clicks, signup intent, useful comments, and follow-up actions |
| Prep discipline | Finalizes copy and visuals during the launch window | Locks assets, proofreads links, and keeps one approved version of each asset |
| Distribution plan | Posts once and hopes discovery carries it | Prepares supporting posts, direct outreach, and a simple traffic capture path |
| Response ownership | Replies ad hoc when someone notices | Assigns one owner to Product Hunt responses and one backup for escalation |
| Post-launch conversion path | Lets attention fade after day one | Routes interest into waitlist, demos, onboarding, or customer interviews |
A useful launch guide should push you toward choices you control now. You control whether your page assets are locked, whether your team knows who answers pricing questions, and whether bug reports have a clear route to the person who can fix them. Even if a contractor made the visuals or someone else is helping with promotion, accountability still sits with you.
Go or no go control panel#
Use this checklist before you submit, not after the post is live:
| Check | What to verify |
|---|---|
| Account readiness | Profile is complete, launch access is confirmed, and launch-day prerequisites are verified |
| Asset lock | Final tagline, description, visuals, CTA, and destination link are approved in one shared doc; every live URL works from a clean browser |
| Role ownership | One person owns replies, one watches analytics and bug reports, and one can approve message changes fast |
| Escalation path | You know what happens if billing breaks, the landing page goes down, or a comment surfaces a serious misunderstanding |
| First-comment readiness | Draft the first comment early with the core value, who it is for, what kind of feedback you want, and a short evidence pack |
- Account readiness
Your profile is complete, launch access is confirmed, and your launch-day prerequisites are verified.
- Asset lock
Final tagline, description, visuals, CTA, and destination link are approved in one shared doc. Click every live URL from a clean browser and confirm the signup or checkout path works.
- Role ownership
One person owns replies, one person watches analytics and bug reports, and one person can approve message changes fast. If you are solo, name the order you will handle those jobs.
- Escalation path
You know what happens if billing breaks, the landing page goes down, or a comment surfaces a serious misunderstanding. One common failure mode is spending the launch window debating instead of fixing because nobody owns escalation.
- First-comment readiness
Draft your first comment early, including the core value, who it is for, and what kind of feedback you want. Keep a short evidence pack ready too: screenshots, pricing clarification, onboarding steps, and known limitations.
If those checks are shaky, wait. If they are solid, launch and focus on capturing durable interest, not just launch-day noise. The next step is building a path that catches that interest cleanly: How to Build a Waitlist for Your SaaS Product Launch. Related: A guide to 'Maslow's Hierarchy of Needs' for understanding client motivation.
What Is a Product Hunt Launch System and Why Does It Beat Tips Lists?#
A Product Hunt launch system beats a tips list because it makes every action pass three checks: phase, owner, and measurable output. Tips like "build momentum" are directionally useful, but they break down under pressure if nobody owns the work or decides what changes when feedback lands.
Launch dynamics move quickly: upvotes and comments happen in public, and many teams treat launch day like a limited-shot event. Your model needs to be operational, not inspirational.
| Execution area | Tips list behavior | System behavior |
|---|---|---|
| Ownership | Everyone is "helping" | One named owner per phase, plus backup |
| Triggers | Reacts when something feels urgent | Uses explicit triggers: asset lock complete, repeated comment theme, signup drop, confirmed bug |
| Response loop | Replies stay in comments or chat | Feedback is logged, grouped, and routed into message updates, onboarding fixes, or backlog priorities |
| Follow-through artifacts | Launch ends when traffic slows | Leaves artifacts: approved asset doc, first-comment draft, issue log, message-change log, post-launch action list |
Pre-launch readiness#
Your pre-launch owner is the launch lead, and the decision point is simple: go or no-go. If core assets or roles are unclear, you do not launch.
Use Product Hunt before launch so you understand the mechanics in practice: complete your profile, follow relevant topics, and comment. Set your teaser page and launch date early enough to sequence prep, and avoid short notice if you plan to activate supporters.
Launch-day execution#
Your launch-day owner is the response lead, and the decision point is: update messaging, fix product or onboarding, or hold. Ranking is influenced by upvote quantity and quality, but your job is to manage what you can verify in real time.
Track concrete signals you control: comment themes, referral clicks, signup starts, demo requests, and repeated objections. If you need a platform benchmark in this section, verify the current figure against platform analytics or source records before using it.
A practical routing example: if early comments repeatedly show unclear audience fit, pricing confusion, and an onboarding blocker, your response lead answers publicly and updates core messaging, your onboarding owner fixes or clarifies the broken step, and your product owner logs the repeated request with priority. Feedback becomes action, not noise.
Post-launch compounding#
Your post-launch owner is growth or product, and the decision point is what gets converted into durable improvements after day one. Keep the outputs concrete: cleaned comment log, copy updates, onboarding fixes, bug tickets, interview invites, and a short objection summary.
Use this filter rule: keep only actions that map to a phase, an owner, and a measurable output. Cut everything else.
You might also find this useful: A Guide to Building a 'Trust-First' Product Roadmap.
Are You Ready to Launch Now or Are You Still Guessing?#
You are either launch-ready or still carrying preventable risk. Treat this as a go/no-go decision based on evidence, not effort or confidence.
Preparation time alone is not a reliable signal. Reported outcomes range from long prep that did not get featured to very short prep that still reached a top promoted spot, so readiness should be judged by artifacts, ownership, and fallback coverage.
| Gate | Ready evidence (artifact) | Owner and fallback | No-go trigger |
|---|---|---|---|
| Submission packet | One approved doc with final tagline, description, visuals, destination link, pricing note, known limits, and first comment | Launch lead owns final lock; backup can publish the locked draft | Core listing fields are still changing |
| Message-market fit | In a clean-browser review, a new visitor can identify the problem, follow the demo narrative, see the CTA path, and find the main objection answer | Launch lead + product owner run the review; backup reviewer confirms clarity | Test reviewers still ask basic "who is this for?" or "what should I do next?" questions |
| Response coverage | Named response lead for comments, plus a clear route for bugs and product questions | Response lead owns triage; backup responder is scheduled for launch coverage | Replies depend on whoever is online at the moment |
| Amplification plan | Support asks are consent-based; outreach uses owned social and internal channels (for example Slack or newsletter) | One owner sends approved asks and stops when consent is absent | Plan includes unsolicited vote requests or paid engagement offers |
Before you go live, run one final click-through from listing to signup to onboarding and back. Many launch-day failures come from preventable path confusion, not lack of interest.
Platform activity benchmark: Current platform benchmark pending analytics/source-record verification.
Decision protocol: if any critical gate fails, delay and fix it. If all critical gates pass, launch and lock the execution plan to avoid last-minute changes under pressure.
We covered this in detail in The Pre-Launch Checklist for a Digital Product.
When Is the Best Day to Launch on Product Hunt?#
Launch when your operation is ready, not when the calendar feels lucky. Product Hunt's core guidance is still the right rule: "The best day to launch is when you're ready."
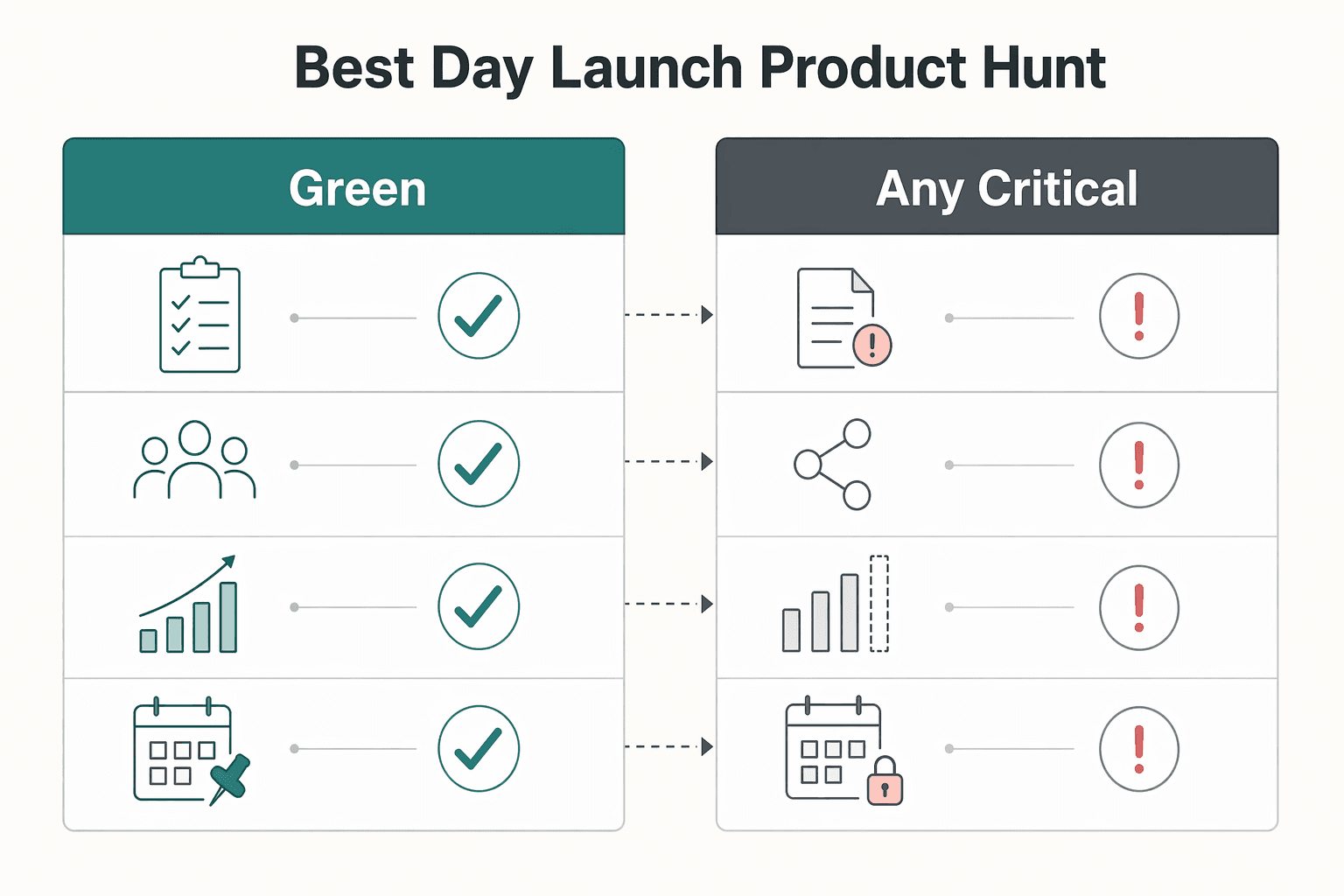
Use timing as a go/no-go decision across readiness, distribution, and execution coverage. If any one is not ready, the date is wrong.
| Readiness state | Channel warmth | Team coverage and fallback | Decision |
|---|---|---|---|
| Green | Warm | Launch-day replies and issue routing are staffed, with a named backup | Launch now |
| Green | Cold | Coverage exists, but demand is not warmed | Delay and warm your list, social, or waitlist first |
| Green | Warm | No real fallback if the lead drops | Delay until backup coverage is confirmed |
| Green | Warm | Coverage is solid and you have a relevant external moment (for example, an announcement or event) | Align timing to that moment, then launch |
| Any critical item is red | Any | Any | Delay and fix the blocker |
You will keep hearing weekday vs weekend takes in community threads. Treat those as secondary signals, not primary decision criteria.
- Current platform timing guidance pending platform/source-record verification.
- Current weekend performance signal pending analytics/source-record verification.
Scheduling checklist before you commit:
- Readiness is green.
- Distribution is warm enough to matter.
- Launch-day and next-step coverage are staffed with a fallback owner.
- If any one is red, delay and resolve that blocker.
For a step-by-step walkthrough, see A Guide to Product-Led Growth (PLG) for SaaS Startups.
How Do You Execute Launch Day Without Dropping Operational Balls?#
Run launch day as a managed shift, not a posting event. Treat it as the launch phase inside a larger system, with clear outputs for each block so you can keep response quality steady whether traction is high or low.
Use one live operating surface for your listing, comments, signup flow, and internal issue queue. Your objective is to give clear public answers, catch friction early, and finish with a clean handoff into post-launch work.
| Time block | Monitoring signals | Operator outputs | Issue triage path | Handoff note |
|---|---|---|---|---|
| Opening window | New comments, early questions, first issue reports, signup friction | Replies inside your internal reply SLA, first clarifications, routed access or bug tickets | Route blockers to escalation owner immediately; keep non-blockers with primary or backup | Log unresolved questions, owner, and current status |
| Midday pulse | Recurring objections, message confusion, repeated asks, support volume | Tightened response language, updated FAQ snippets, active status notes | Escalate repeated confusion tied to product or onboarding gaps | Record what changed in messaging and why |
| Later-day pulse | Slower threads, deeper product questions, lead quality, promised follow-ups | Higher-context replies, explicit follow-up commitments with owner or status | Keep product-depth questions in escalation queue until resolved | Separate warm pipeline follow-up from general feedback |
| End-of-day handoff | Open issues, unanswered comments, repeat objections, onboarding drop-offs | Day-two task list, ownership list, onboarding, product, or pipeline actions | Confirm each open loop has next action and owner | Hand off status, next step, and deadline for each open item |
For a solo or lean team, still assign three roles, even if one person covers two:
- Primary owner: posts, replies, and maintains message consistency.
- Backup owner: takes over if the primary is blocked or overloaded.
- Escalation owner: handles items that need product, engineering, or customer-success decisions.
Before going live, run one verification pass: owner access, approved positioning, tracker link, and escalation route. This prevents common failures, like public replies continuing while a real blocker sits unowned in a private thread.
Use one tracker as an incident-and-feedback loop, not a loose notes doc. Keep one row per item with: comment or issue, category, public answer needed, owner, status, promised follow-up, and impact area (onboarding, product, or pipeline). This keeps open questions, recurring objections, and public commitments in one place.
Stay flexible as feedback comes in. If the same confusion repeats, update the core explanation and route related fixes rather than patching one-off replies.
By day end, success is a usable operating record: what users asked, what broke, what you promised, and who owns next actions. That is your bridge to post-launch follow-through, where comment insights become onboarding fixes, product updates, and pipeline actions.
Related: A freelancer's guide to 'Influence: The Psychology of Persuasion'.
What Happens After Day One and When Should You Relaunch?#
Day two through week two is where launch value is won or lost. Run a fixed sequence: capture feedback, triage by impact, ship visible fixes, publish updates, and move the learning into onboarding and docs so the same confusion does not keep costing you signups.
Product Hunt frames launch as more than a 24-hour event, so treat post-launch as active community work, not a cooldown. Sort repeated comments into three buckets: onboarding friction, product gap, or message gap. Then fix the system, not just the reply: if people keep misunderstanding one point, update listing copy, landing page, and first-run onboarding together. If access is blocked, prioritize that before promotional updates.
Use a simple checkpoint early in week one: can a new visitor understand the product, sign up, and reach first value without needing comment-thread context? If not, your next public post should announce a real fix, not more hype.
When you post updates, keep them specific: what changed, why you changed it, and who benefits now. Then re-engage earlier commenters in their original threads so the update is visible where the issue started. Track outcomes beyond rank: qualified signups, feedback quality, and early activation signals.
| Relaunch question | Strong signal | Weak signal | What you should do now |
|---|---|---|---|
| Did the product change in a significant way? | A major iteration or pivot you can explain clearly | Minor fixes, UI polish, or routine performance work | Relaunch only if you can document material change |
| Did user value clearly shift? | A new use case, user segment, or outcome is now possible | Same core promise with clearer packaging | Keep iterating publicly unless value changed in a meaningful way |
| Do you have evidence of different adoption behavior? | New usage patterns or feedback themes that show changed behavior | Hope that a new date alone will improve results | Collect evidence first, then decide |
| Are you relying on timing alone? | You can explain significant changes and why they matter now | You are retrying for rank without substantive change | Do not relaunch just because time passed |
For relaunch readiness, focus on proof, not the calendar alone. You should be able to explain the significant iteration, show what changed, and make the new user value obvious in your product flow and supporting materials. If you are still driving external interest, route people into a controlled next step, such as a waitlist or segmented signup path: How to Build a Waitlist for Your SaaS Product Launch. Related reading: A Guide to Direct Booking Websites for Vacation Rentals.
Build a Risk Aware Launch Workflow You Can Audit Later#
Treat this as your post-launch audit system, not extra process. If you document who made each call and what evidence supported it, you can defend decisions, repeat what worked, and fix what did not.
Use one owner model across every launch channel: primary owner, backup owner, handoff note, and decision log. Apply it to Product Hunt, your landing page, email, and each amplification channel so execution does not depend on memory when conditions change quickly.
Set channel ownership before launch week#
Set ownership before launch week, then log handoffs as work moves. Your handoff note should capture current status, pending replies, known issues, and anything that should not be promised publicly. Your decision log should include timestamp, decision maker, evidence used, and final action.
For Product Hunt, capture what is publicly visible at launch and after meaningful updates. If a page shows a visible Launch Team / Built With block, keep a screenshot as a public checkpoint tied to your internal log.
If credential access is still ad hoc, fix that before copy rehearsal. Standardize storage and recovery, confirm access, and record change history first. See The Best Password Managers for Freelancers and Teams.
| Control | Safe default | Evidence to keep | Why this reduces launch risk |
|---|---|---|---|
| Channel ownership | One primary owner and one backup per channel | Owner list, backup list, dated handoff note | Keeps accountability clear and prevents stalled responses |
| Credential management | Shared access only through approved credential storage, reviewed before launch week | Access snapshot, recovery note, access change history | Reduces lockouts, unsafe sharing, and unclear account changes |
| Public conduct rules | Use approved scripts; escalate off-script questions before answering | Approved scripts, escalation notes, reply history | Lowers risk of inconsistent or unsupported public statements |
| Evidence logging | Log support for ranking, user-count, and update claims before repeating them | Decision log, screenshots, source labels (for example, self-reported) | Prevents repeated claims from being treated as verified facts |
| Escalation | Route unresolved policy, billing, or legal questions to verified support or legal review | Support ticket note, legal review note, final resolution entry | Avoids confident public commitments that may be wrong |
Keep conduct and claim evidence, not just intent#
Your protection is the artifact trail, not memory. Keep the exact scripts used, access snapshots before launch and after account changes, escalation notes for unresolved questions, and change history for listing copy, landing page text, onboarding text, and launch emails.
| Artifact | What to keep |
|---|---|
| Scripts | The exact scripts used |
| Access snapshots | Access snapshots before launch and after account changes |
| Escalation notes | Escalation notes for unresolved questions |
| Listing copy | Change history for listing copy |
| Landing page text | Change history for landing page text |
| Onboarding text | Change history for onboarding text |
| Launch emails | Change history for launch emails |
Without that record, a partial claim can spread from comments to social to support, and you cannot trace where it shifted.
Use qualified language when the market or law is not fully settled#
When a claim is market-dependent or compliance-sensitive, use a simple communication rule: qualify the statement, document assumptions, and escalate unresolved points before public commitments.
| Claim area | Handling rule |
|---|---|
| Market-dependent or compliance-sensitive statements | Qualify the statement, document assumptions, and escalate unresolved points before public commitments |
| Legal references | Verify against official editions and keep the official PDF link, date, and document ID in your log |
| Convenience summaries | Do not treat convenience summaries as binding authority |
| Court syllabus | Do not treat a Court syllabus as part of the binding opinion |
| Launch metrics from distributed press content | Label them as self-reported unless you independently corroborate them |
If legal references are involved, verify against official editions and keep the official PDF link, date, and document ID in your log. Do not treat convenience summaries as binding authority, and do not treat a Court syllabus as part of the binding opinion. For launch metrics from distributed press content, label them as self-reported unless you independently corroborate them.
After launch-day traffic, keep continuity controlled. If needed, route interest into a waitlist or segmented intake and document how leads move into onboarding. Use How to Build a Waitlist for Your SaaS Product Launch for that workflow moment.
If your model is service-led rather than product-led, use How to Build a Waitlist for a New Freelance Service.
Run This Playbook and Launch With Fewer Surprises#
Run your launch as a three-phase operating shift: prep, launch day, and post-launch follow-through. This structure helps you make controlled decisions when traffic, comments, and internal requests all hit at once.
A smaller, clean launch usually beats a bigger, messy one. If your product struggles under small traffic spikes, your audience is still unclear, or you cannot stay present for most of launch day, delay and fix that first.
| Phase | What you do | What stays fixed | Adaptation rule | Evidence to keep |
|---|---|---|---|---|
| Prep | Finalize listing assets, first comment, handoff note, and reply standards. Make a go/no-go call based on readiness. | Audience, core claim, owner assignments | Adjust timing and outreach plan, but do not relax readiness gates. | Readiness decision note, final asset set, owner coverage log, approved copy |
| Launch day | Keep a primary owner and backup active, monitor comments, reply quickly, and route issues into one live record. | Message discipline, response quality, change-approval path | Re-prioritize replies and escalation based on live demand, while keeping claims and tone consistent. | Response log, issue log, screenshots, handoff updates |
| Post-launch | Follow up with interested users, convert feedback into fixes, and record what changed. | Success definition beyond rank: qualified visits, useful feedback, completed next steps | Reorder fix priority and distribution follow-up based on what you learned, without rewriting your success criteria. | Post-launch improvement log, feedback backlog, follow-up tracker, dated change log |
In prep, prove readiness instead of assuming it. A practical check is owner coverage: if you cannot respond quickly for roughly 12 to 16 hours, you are undercovered for the launch you want. If you have capacity, setting a date and teaser about 3 weeks in advance can help you sequence support, but lead time does not replace readiness.
On launch day, keep one shared document open and current. Log who replied, what changed, what broke, and what needs follow-up. The first four hours may matter for momentum, but do not let that push you into risky behavior. If anyone suggests giveaways, incentives, or vote-seeking tactics, verify the current platform rule from platform policy or source records before using or approving the tactic.
After day one, your leverage is follow-through. If comments reveal onboarding confusion, update page copy, answer the question publicly, and push the fix into your product queue with an owner and date. Product Hunt is not automatic traffic, so your post-launch improvement log matters more than a temporary rank screenshot.
If your launch claims depend on regional availability, supported countries, or program access, verify that before publishing. If you want a second review of those claims, contact Gruv to confirm country or program support before launch day.
Need the full breakdown? Read A guide to 'Rebranding' an existing business.
Frequently Asked Questions
What is the safest definition of success for a Product Hunt launch if I do not hit number one?
Define success before launch as three things you can verify: qualified visits, useful feedback, and a clear next step completed by the right people. That is safer than rank chasing because the leaderboard changes throughout the day and the exact formula is not public. Set those three measures in writing, then route post-launch interest into a controlled intake such as How to Build a Waitlist for Your SaaS Product Launch.
Should I launch now or wait one more week?
Wait if your readiness gate is not fully green. If your listing assets are still moving, your first comment is not finalized, your primary and backup owners are unclear, or your follow-up path is still a generic homepage, you are not ready. Your next action is a dry run: open the draft, confirm owner coverage, and save screenshots of the exact version you plan to publish.
What should I prepare before I submit on Product Hunt?
Prepare the listing copy and assets, your first comment, your owner and backup owner, a short handoff note, and a place to log comments, issues, and decisions as they happen. Using Product Hunt is free, but launching without control of details can still create avoidable risk. Your next action is to name one person to submit, one person to monitor and reply, and one shared record where approved copy and evidence live.
What should I do if my product appears lower than expected or I suspect spam on launch day?
Do not guess how the ranking works or start making public accusations. Lower placement can reflect factors you cannot verify from the outside, including spam detection. Your next action is to capture screenshots, use the 3-dot report option on suspicious activity, and use site chat if the issue needs team review during launch.
Can I relaunch on Product Hunt, and when is it actually justified?
The guidance here does not confirm a fixed relaunch timing rule. If you are considering a relaunch, document what is materially different, keep dated evidence, and check current Product Hunt guidance or contact support before you proceed. Your next action is to keep a dated change log with screenshots, user notes, and a short statement of what is materially different now.
What should my first comment do?
Use your first comment to set the conversation. Tell people who the product is for, what problem it solves right now, and what kind of feedback you want so your launch-day owner can sort replies quickly. Your next action is to draft it before launch, have someone check it for unsupported claims, and save the final version in your decision log.
How much should I rely on outside launch advice?
Treat outside advice as optional input, not as your source of truth. Product Hunt’s own guidance is the better baseline, and the algorithm details are intentionally not public. Your next action is to compare any outside tactic against the official Product Hunt launch guidance and your own launch data before you use it.
What if someone else submits my product first?
Move quickly and keep the response private and factual. If you contact Product Hunt right away, they may be able to remove the product and let the community member know a launch is on the way. Your next action is to have your primary owner open site chat immediately and save the support note in the same evidence folder as your launch screenshots.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
- ecfr.gov/current/title-28/chapter-I/part-35trusted
- ecfr.gov/current/title-30/chapter-II/subchapter-B/par...trusted
- federalregister.gov/documents/2024/10/15/2024-22905/cybersecurit...trusted
- federalregister.gov/documents/2024/10/15/2024-22905/cybersecurit...trusted
- fema.gov/sites/default/files/documents/fema_iappg-1.1...trusted
- lis.virginia.gov/bill-details/20261/HB271/text/HB271HC1trusted
- mn.gov/deed/business/starting-businesstrusted
- pa.gov/content/dam/copapwp-pagov/en/budget/document...trusted
Educational content only. Not legal, tax, or financial advice.
Related Posts

The Best Password Managers for Freelancers and Teams
A client asks for an urgent file, you open their portal, and the login fails. Ten minutes later your invoicing app wants a reset too. That is why your password setup is a business risk, not just a nuisance. Weak credential habits can turn one mistake into wider account access problems, then into delivery delays and cleanup work.

How to Build a Waitlist for Your SaaS Product Launch
Your waitlist should lower launch risk, not create cleanup work the week you open access. Treat your waitlist as a control layer for readiness: who signs up, what intent they show, what promise they heard, and what has to be true before you invite the next group.

How to Build a Waitlist for a New Freelance Service
**Build your freelance waitlist like an operator: treat it as a controlled intake pipeline, not just a "collect emails" project.** You're the CEO of a business-of-one. Your waitlist is how you control demand without letting demand control your calendar. The goal is simple: avoid calendar chaos during your next service launch and keep records clean if you ever need to explain who got offered what, when, and why.