
Quick Answer
GraphQL can work well for client-facing consulting when you use the schema as the contract, let clients adjust queries within that contract, and manage schema changes through explicit review. That setup makes scope visible, reduces rework, and speeds frontend iteration, while REST or a hybrid approach may be safer for simple, stable resources or when endpoint-level caching is the priority.
A strong consulting practice is built on trust. What usually erodes that trust is not the hard technical work. It is scope creep, communication gaps, and the steady admin load of "small" requests that quietly drain margin. Many teams treat those problems as inevitable. More often, they point to a weak contract between you and the client.
This is not mainly a debate about API style. It is a practical way to use GraphQL as a business tool, to make scope visible, let clients move faster inside clear boundaries, and keep change manageable as the product evolves. Used this way, it helps you work less like a reactive service provider and more like the person who set the rules of engagement from the start.
Pillar 1: The Schema as an Ironclad Contract#
If you want scope control to hold under pressure, treat your schema as the operating contract, not just technical documentation. In GraphQL, the schema is the API contract, and it is introspectable by design. The agreed surface area is visible to both you and the client before work turns into drift.
That matters because the schema defines the intended API surface. When a client asks for a new field, a new mutation, or a changed shape, you have an objective checkpoint. Is it already in the contract? If not, it is not "just a small tweak." It is a scoped change.
That check is useful, but it is not the whole story. Schema correctness does not guarantee system correctness. Production issues still show up in cross-component interactions that the contract alone will not catch.
One practical way to run it:
- Review the schema at kickoff and align on the initial fields and mutations.
- When a change request appears, check the schema diff before estimating.
- Treat new fields or mutations as contract updates, then scope commercial impact before delivery.
| Situation | Ambiguous request flow | Schema-governed request flow |
|---|---|---|
| Scope control | Debated in meetings and message threads | Checked against the current schema |
| Rework risk | Often high, because intent is implied | Often lower when the API surface is explicit |
| Billing clarity | Easy to blur into "small fixes" | Clearer to scope and price as contract change |
There is also a client autonomy benefit, but it helps to keep it concrete. Introspection can support shared API docs, typed clients, and contract-aware tooling such as Apollo GraphOS. That lets the client team inspect what exists without waiting on you for every clarification.
Use one rule consistently: if a request is not represented in the schema, route it into scoped change management instead of ad hoc delivery. Related: How to Calculate ROI on Your Freelance Marketing Efforts.
Pillar 2: Client Queries as a Toolkit for Mutual Velocity#
You keep delivery moving when the client team can change queries inside the existing schema instead of opening a backend ticket for every view update. In GraphQL's client-driven model, they request the fields they need, while the strongly typed schema defines what is available.
This is where over-fetching and under-fetching become practical, not theoretical. Over-fetching is requesting more fields than a screen uses. Under-fetching is needing extra requests because one response does not include enough data. Field selection discipline helps reduce both, often by shaping one operation around one screen or user action.
Where query ownership starts and ends#
Use one clear rule: if the field or relation already exists in the schema, treat it as a client query change, not a backend feature request. That usually covers adding an existing field to a screen, removing unused selections, or adjusting operation shape for a component.
When the request goes beyond the current schema, move it into scoped change management.
| Client request | Can self-serve with query change? | Next path |
|---|---|---|
| Add an existing field to a screen | Yes | Frontend updates operation |
| Remove fields no longer needed | Yes | Frontend trims selection set |
| Use an existing relation in one operation | Yes, if it is already in schema | Frontend updates operation |
| Add a new field, mutation, or object shape | No | Scope and approve schema change |
| Access data outside current authorization rules | No | Scope security + schema change |
Guardrails for safe autonomy#
Client query freedom still needs production governance. Keep query behavior and access controls explicit within your implementation of schema/endpoint management, security, caching, and DevOps.
| Guardrail | Detail |
|---|---|
| Query complexity controls | For expensive request shapes |
| Depth limits | To prevent pathological nesting |
| Persisted-query workflows | Where you want tighter control of allowed operations |
| Field-level access enforcement | In authorization and resolver logic |
Practical guardrails you can define up front:
- Query complexity controls for expensive request shapes.
- Depth limits to prevent pathological nesting.
- Persisted-query workflows where you want tighter control of allowed operations.
- Field-level access enforcement in authorization and resolver logic.
A short operating checklist#
| Checklist item | Detail |
|---|---|
| Query ownership | Define query ownership for existing schema fields (typically frontend-owned) |
| Escalation triggers | Document escalation triggers for new schema needs and authorization-impacting requests |
| Recurring query patterns | Review recurring query patterns and promote stable patterns into better schema design |
Handled this way, you get fewer interruption tickets, clearer ownership boundaries, and faster iteration without constant ad hoc endpoint work. You might also find this useful: The Best API Documentation Tools for Developers.
Pillar 3: Schema Evolution as Future-Proofing Insurance#
You keep client trust when schema changes are predictable for active consumers. In practice, that means favoring additive updates where possible, and treating removals as planned migrations with explicit checks.
A typed schema makes this workable because fields, arguments, and return types are explicit. Adding a field or relation is usually easier for consumers to absorb because clients only receive what they request. Renames and removals are riskier, so handle them with a defined workflow instead of ad hoc cleanup.
Make change management explicit#
Use the schema diff as your primary review artifact, with the generated API reference as the current-state checkpoint before and after each release. For each change, confirm:
| Review item | What to confirm |
|---|---|
| Schema diff | What changed in the schema diff |
| Affected consumers | Which consumer apps or teams are affected |
| Migration note | What migration note each consumer should follow |
| Removal plan | Whether removal is planned, and under what verified condition |
Because GraphQL traffic can run through one /graphql endpoint, route-level checks alone are not enough to prove compatibility. Also, in at least one documented GraphQL API, HTTP status can still be 200 when execution errors occur, so your compatibility checks should inspect response bodies and the errors field.
| Change model | Maintenance load | Client disruption risk | Delivery continuity |
|---|---|---|---|
| Versioned REST release cycle | Higher, because multiple resource versions and docs may run in parallel | Higher during version migration windows | Often split across staggered releases |
| GraphQL additive evolution | Lower for that release when consumers can keep existing selections | Lower when current consumers do not need immediate query changes | Stronger continuity from one evolving schema |
| GraphQL retirement flow (old + replacement during migration) | Moderate while both paths are supported | Depends on communication quality and compatibility checks | Good when retirement is verified and scheduled |
Deprecation is a process, not just a marker#
A marker like @deprecated helps signal intent, but it is not the full policy. You still need clear changelog ownership, a communication cadence with consuming teams, and CI compatibility checks tied to real consumer operations.
That is how you reduce operational surprises: fewer emergency rewrites, cleaner handoffs between client teams, and more predictable long-term support scope.
Before shipping a schema change, run this checklist:
- Classify the change type (additive, behavior change, or retirement).
- Document the migration path in the changelog and consumer note.
- Verify the retirement timing policy against current source records before publishing a cutoff.
For a step-by-step walkthrough, see The Best Code Editors for Web Developers in 2026.
A Strategic Choice: GraphQL vs. REST for the Modern Consultant#
Choose this as a delivery-risk decision first: pick the API style that gives your client clearer scope boundaries, fewer rework loops, and predictable maintenance commitments.
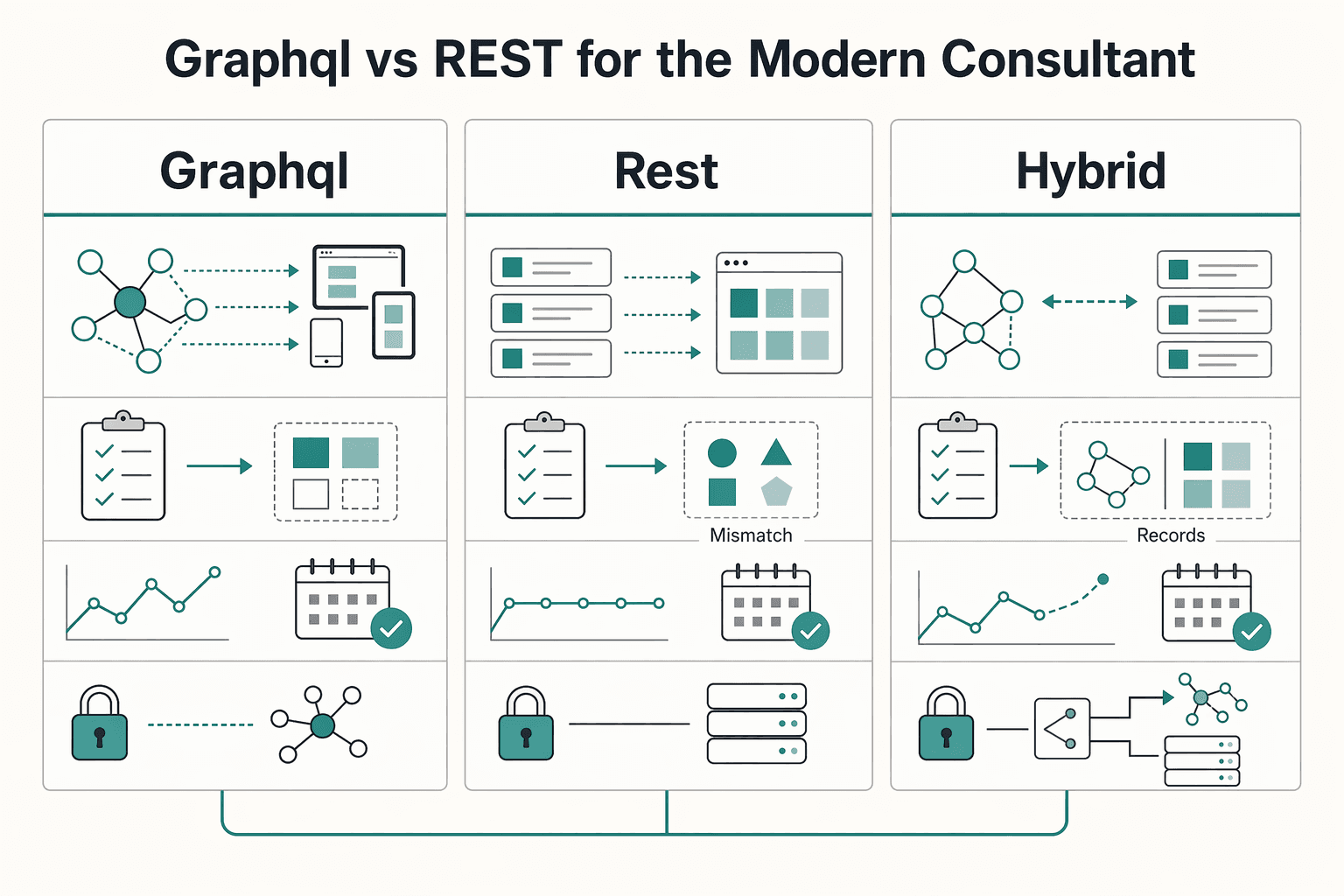
GraphQL is usually a stronger fit when data is relationship-heavy, multiple consumers need different shapes, and requirements change during delivery. REST is often lower risk when resources are simple and stable, and the team wants a familiar model with less specialized tooling overhead.
GraphQL lets clients request only what they need and pull related resources in one query through a unified endpoint. REST can be cleaner when resource shapes are already well understood, but endpoint design still needs care: overly generic endpoints can lead to overfetching, while overly specific endpoints can increase round trips.
| Approach | Best fit | Team query maturity | Change frequency | Integration complexity | Operational overhead |
|---|---|---|---|---|---|
| GraphQL | Relationship-heavy domain data across multiple consumers | Medium to high, or willing to build query/schema discipline | Frequent UI/reporting changes | Lower for related-data retrieval through one endpoint | Higher upfront due to tooling and schema governance |
| REST | Simple, stable resources with predictable shapes | Low to medium | Low to moderate | Can increase when clients need many related resources across endpoints | Usually lower upfront; often easier where REST is already established |
| Hybrid | Mixed estate where one style would overfit part of the problem | Medium | Mixed | Lower risk by matching interface to job | Moderate, because you operate both styles intentionally |
A hybrid model is often the practical consultant choice. Use GraphQL where connected data drives screen and report requirements, and keep REST where existing resource endpoints already work well and change slowly. In WordPress 6.6, core includes 21 REST endpoints, which can reduce initial integration effort if that surface already matches the client's stable needs.
For discovery calls, pressure-test the choice with concrete examples:
- How many consumer apps need the same data in different shapes?
- How often do screen/report data requirements change?
- Where are teams currently seeing overfetching or extra round trips?
- What existing endpoint surface must remain intact?
- Who owns schema or endpoint change review after launch?
- Which org-specific cutoff would trigger introducing GraphQL, and what current source records verify it?
If you want a deeper dive, read Value-Based Pricing: A Freelancer's Guide.
From Service Provider to Strategic Partner#
Treat GraphQL as a delivery model, not just a query language: your core deliverable becomes a strongly typed schema that defines what is in scope and how changes are handled.
In practice, that changes your kickoff workflow. Ask for one real screen or report, the current endpoint inventory, and sample payloads, then map that into a schema draft the client can review. A concrete artifact, such as a Project type with contributors(first, after), makes scope visible early. If required data is missing from that schema, treat it as a formal schema change request with explicit impact, not an informal tweak.
| Area | Service-provider mode | Strategic-partner mode |
|---|---|---|
| Scope control | Scope is tracked in tickets and endpoint requests | Scope is tracked in the schema artifact and agreed query surface |
| Client autonomy | Client asks you for each new payload shape | Client requests what they need within the supported schema contract |
| Delivery risk | Gaps surface late during implementation | Gaps surface earlier during schema review (types, fields, arguments) |
| Pricing posture | Priced around ad hoc endpoint work | Priced around contract design, migration slice, and change policy |
Keep the tradeoff explicit: real GraphQL implementations are rarely trivial. You still need clear modeling decisions (domain model vs use-case model), and adding a GraphQL orchestration layer over multiple services can increase implementation complexity even when it simplifies client access through one endpoint.
Use this mini-checklist in your next kickoff:
- Start with a first-pass schema sketch, not just endpoint ideas.
- Validate that sketch against one real client screen before final pricing.
- Document how schema changes are proposed, approved, and released.
- Define which domains remain on REST and which move behind GraphQL.
We covered this in detail in A Guide to Using Vercel for Frontend Deployments.
Frequently Asked Questions
How should you price this work if you are moving a client toward GraphQL?
Price the initial migration slice, not a full replacement. Scope it around one use case, only the schema surface needed for that use case, and whether you will start by wrapping a single existing REST call. If discovery is incomplete, use a phased estimate instead of a fixed quote.
How do you keep queries from becoming unsafe or expensive?
Review query shape early in a small pilot. Test caching assumptions before broad rollout because server-side caching can be more challenging with GraphQL. Keep authentication and authorization rules in your business logic layer, and have resolvers call into that layer.
What onboarding should you expect for the client team?
Start with one use case and only the schema needed for that. Broad tooling support can help handoff and onboarding, including explorer GUIs, editor integrations, code generation, linting, and analytics.
Why is the schema a clearer contract than docs alone?
Treat the typed schema as the technical contract that determines which queries are supported. It helps API evolution because you can reduce breaking changes and use built-in deprecation support instead of relying only on prose updates. Docs still matter for examples, auth notes, and operating rules, but they are not the executable API contract.
When is REST still the better fit?
REST is often the better fit when endpoint-level server caching is a top priority and response structure per endpoint is stable. Endpoint responses are easier to cache with REST, while GraphQL caching can be more involved.
Do you need to replace REST all at once?
No. A low-risk start is a single HTTP request that wraps an existing REST call, then expand only if that first slice proves useful. You can also expose existing REST endpoints through GraphQL with root resolvers to keep scope tighter than a full rewrite.
How should you handle a hybrid architecture without confusing the client?
Write down which data domains belong behind GraphQL, which stay on REST, and who approves changes on each side after launch. Start with one use case and build only the needed schema surface. Keep a short policy note for when to extend the schema versus keep or add a REST endpoint.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 7 external sources outside the trusted-domain allowlist.
- aichat.physics.ucla.edu/fetch.php/textbook-solutions/asrWzm/Code_Gra...trusted
- 103.203.175.90/fdScript/RootOfEBooks/E%20Book%20collection%...external
- allmultidisciplinaryjournal.com/uploads/archives/20250328131524_F-23-217.1.pdfexternal
- apollographql.com/why-graphqlexternal
- archive.fosdem.org/2025/schedule/pdf/a3.pdfexternal
- arxiv.org/html/2408.08363v1external
- docs.horizon3.ai/api/graphqlexternal
- fortbridge.co.uk/pentesting/ultimate-guide-to-api-pentesting-...external
Educational content only. Not legal, tax, or financial advice.
Related Posts

Value-Based Pricing for Freelancers Under Real Payment Risk
Value-based pricing works when you and the client can name the business result before kickoff and agree on how progress will be judged. If that link is weak, use a tighter model first. This is not about defending one pricing philosophy over another. It is about avoiding surprises by keeping pricing, scope, delivery, and payment aligned from day one.

How to Calculate ROI on Your Freelance Marketing Efforts
If you want ROI to help you decide what to keep, fix, or pause, stop treating it like a one-off formula. You need a repeatable habit you trust because the stakes are practical. Cash flow, calendar capacity, and client quality all sit downstream of these numbers.

The Best API Documentation Tools for Developers
If you are comparing the **best api documentation tools** for your team, do not start with the slickest demo. Start with the stack you can actually own, review, roll back, and maintain when releases get busy. If that discipline is weak, a prettier portal can hide the problem until documentation drift shows up.