
Quick Answer
Start with gall's law for complex systems by running a Minimum Viable Compliance setup first: one invoicing flow, one residency day counter, and one payment channel you can review end to end. Add complexity only after a real operational signal appears, then make the smallest verified change and record what changed so your process stays usable under growth.
Gall's Law: Your New Operating Manual for Managing Complexity#
Build in stages, not all at once. Gall's Law is not abstract theory here. It is a practical rule for designing processes and systems without ending up with a brittle mess you have to untangle later.
John Gall's core observation is simple: complex arrangements that work usually grow out of simpler ones that already work. The warning matters just as much. When you design a fully complex setup from scratch, you often cannot patch it into reliability afterward. In plain English, do not start by building your forever setup. Start by proving one small version in the real world, then expand from there.
That matters because a system is not one thing. It is a set of connected parts. One workflow can affect upstream inputs, downstream approvals, reporting, and storage. As those links multiply, small changes can create larger side effects.
As you add more moving parts, the number of interactions rises fast. A simple way to see the scale is this: 10 components create 45 pairwise interactions, while 100 create nearly 5,000. That is why "just adding one more tool" rarely stays small.
According to the interaction math behind Gall's Law, the jump is not linear. In 2026 terms, a workflow that feels 95% reliable at one step can still become noisy when approvals stack and one layer slips to 90%, then 85%, or even 80% reliability. Even a 5% error rate repeated across handoffs is enough to justify simplifying the baseline before you add another tool.
What a Working Baseline Actually Looks Like#
A working baseline is not a perfect system. It is the smallest setup that can survive contact with reality. For most teams, that means one end-to-end path that consistently completes correctly.
| Baseline element | What it means |
|---|---|
| Working baseline | The smallest setup that can survive contact with reality |
| End-to-end path | One end-to-end path that consistently completes correctly |
| Default process | One default process you actually use, not multiple versions competing in parallel |
| Route from input to outcome | One route from input to outcome that does not require ad hoc fixes each cycle |
| Artifact storage | One place where the key artifacts for that path are easy to find |
| Expansion checkpoint | Confirm the current setup works end to end |
In practice, that usually means one default process you actually use, not multiple versions competing in parallel. It means one route from input to outcome that does not require ad hoc fixes each cycle. And it means one place where the key artifacts for that path are easy to find.
Before you add anything else, use one checkpoint: confirm the current setup works end to end. In product terms, you start with one service working before you integrate the next. Operationally, the rule is the same. If your first path is still producing exceptions, delays, or missing handoffs, do not add another branch, integration, or layer of rules.
How the Grand Design Trap Shows Up in Practice#
Most overbuilt systems do not look dramatic at first. They look responsible. You add extra tools for edge cases you have not hit yet. You create procedures for scenarios that are still hypothetical. You layer approvals before the underlying flow is stable.
The immediate risk is not just annoyance. It is loss of visibility. You stop knowing which version is current, which path is canonical, or where key information lives when a question comes up. The cost also rises in hidden ways. In software, all-at-once builds tend to create mounting costs and complex bugs because of the connections between parts. In operations, the equivalent is mounting coordination time and strange exceptions at handoffs.
A simpler setup is easier to inspect because you can trace it directly. It is easier to adapt because each change touches fewer moving parts.
| Decision point | Design from scratch | Evolve from working baseline |
|---|---|---|
| Trigger | Imagined future scenarios | One real need appears |
| First action | Add several tools, rules, and exceptions at once | Get one path working in one area first |
| Validation signal | Looks complete on paper | A real cycle completes cleanly |
| Next-step rule | Keep expanding "just in case" | Add one component only after the current setup is stable |
The logic is the same as MVP thinking from software development. Start with the smallest version that works, then improve it through feedback. Related: A Guide to Microservices Architecture for SaaS Applications.
The Framework: Introducing "Minimum Viable Compliance" (MVC)#
Minimum Viable Compliance (MVC) means the smallest setup you can run right now that is workable, auditable, and defensible for your current client and jurisdiction mix.
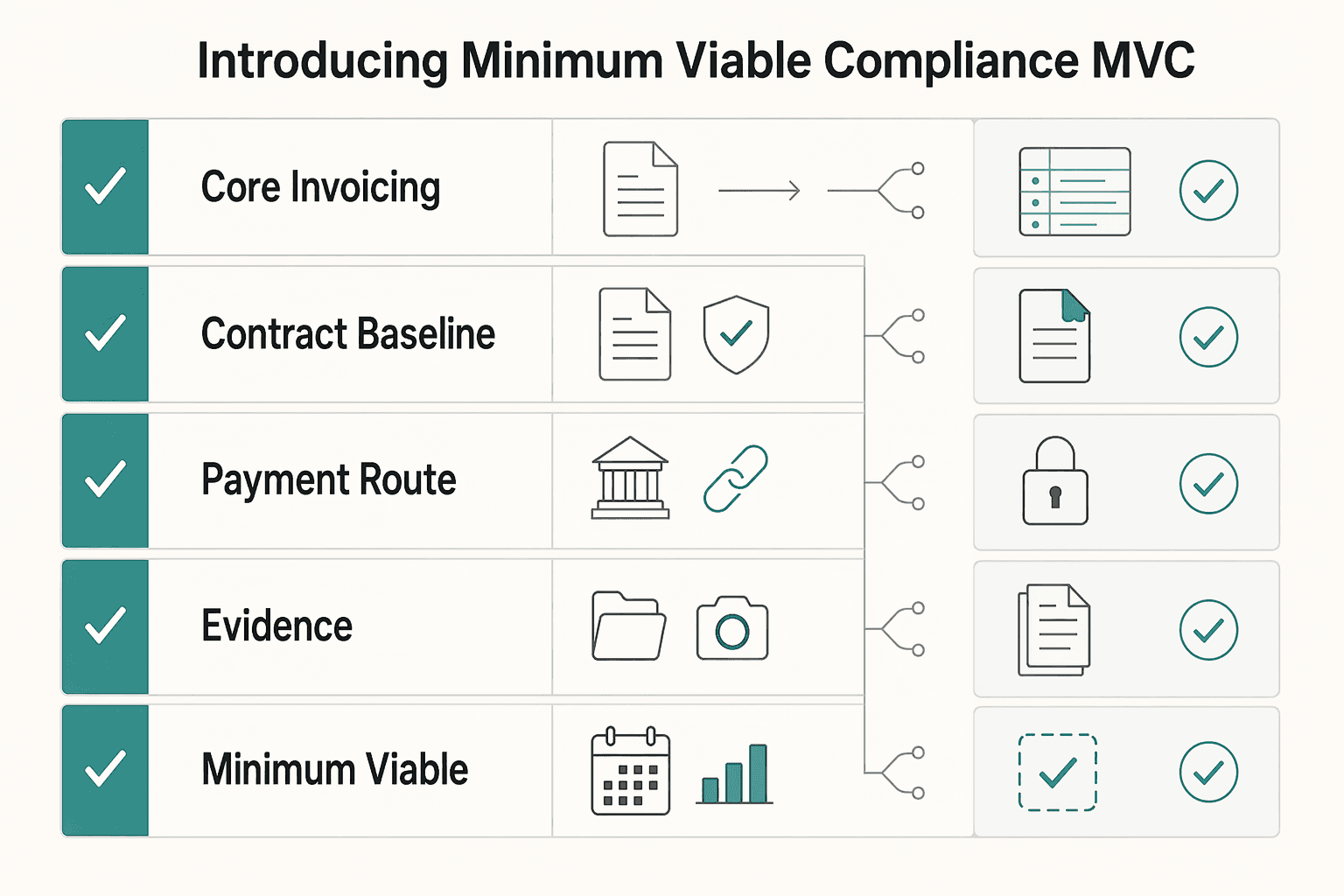
| MVC part | Current baseline |
|---|---|
| Core invoicing path | One core invoicing path you actually use |
| Contract baseline | One contract baseline for your current service |
| Payment route | One payment route with clear account separation |
| Recordkeeping workflow | One recordkeeping workflow that keeps the agreement, invoice, and proof of payment together |
Start with only these four parts:
- One core invoicing path you actually use
- One contract baseline for your current service
- One payment route with clear account separation
- One recordkeeping workflow that keeps the agreement, invoice, and proof of payment together
Use a simple checkpoint: for one real client, can you retrieve that full evidence set quickly? If not, keep the baseline as-is and fix that first.
Defer anything not tied to a real need right now, including extra contract variants, secondary payment processors, complex folder structures, heavy automation, multi-country policy packs, and edge-case rules. The common failure is running multiple versions of the truth before one version works.
| Approach | Objective | Success signal | Failure risk if skipped |
|---|---|---|---|
| Minimum Viable Product | Test whether your offer solves a real customer problem | Someone uses it and gets value | You build too much before demand is proven |
| Minimum Viable Compliance | Keep business operations clean for real work | One full client cycle completes with complete, usable records | You rely on ad hoc steps and cannot clearly defend or audit what happened |
Use one activation rule: keep your baseline unchanged until a real trigger appears, then expand one layer at a time.
- Keep baseline: no change in client mix, jurisdiction mix, service scope, or data handling
- Expand baseline: a real change appears; document the reason, then record the verified requirement before changing the baseline
Step 1 turns this MVC concept into a practical setup checklist. You might also find this useful: A Guide to the Statement of Work (SOW) for a SaaS Development Project.
Step 1: Define and Launch Your Minimum Viable Compliance#
Launch MVC with only three blocks: one invoice path, one residency tracker, and one treasury channel. Build only for your current client and jurisdiction mix, and add anything else only after you verify the rule with an authoritative source for your case.
| Block | Purpose | Pending verification item | Done for now |
|---|---|---|---|
| Invoice | Send accurate invoices for current work and keep a clean record trail | Current local requirement pending verification | One real invoice is sent, paid, and easy to retrieve with the related agreement and payment proof |
| Residency tracking | See risk early and avoid rebuilding your timeline later | Current local threshold pending verification | One simple tracker updated weekly, including where you were and when |
| Treasury | Keep business inflows/outflows visible, searchable, and consistent | Local account-separation requirement pending verification | Business transactions run through that channel, and monthly exports are saved in the same place as related invoice records |
For each block, keep a tiny audit note: source checked, date checked, and decision made. This keeps your setup traceable and reduces guesswork later.
| Block | Minimum setup now | Defer until triggered |
|---|---|---|
| Invoice | One template you actually use for your current service and current client location, with only verified fields/wording | Extra country variants, additional currencies, speculative tax wording, automation |
| Residency tracking | One tracker for the single jurisdiction risk most likely to matter this year, with a verification note and any unconfirmed item marked pending | Multi-country dashboards, edge-case tabs, speculative scenario modeling |
| Treasury | One business payment path with consistent exports and naming rules | Extra processors, multi-currency stacks, fee/FX optimization before volume justifies it |
Invoice#
Set up one invoice flow you can run now and defend later.
- Purpose: send accurate invoices for current work and keep a clean record trail.
- Minimum required inputs: your issuer details, client details as used in your agreement, service description, amount/currency, payment terms/details, and any jurisdiction-specific items only after verification.
- Pending verification: if a local threshold, registration item, or wording rule is unconfirmed, mark it as pending until you verify the live requirement.
- Done for now: one real invoice is sent, paid, and easy to retrieve with the related agreement and payment proof.
Residency tracking#
Track the one location rule most likely to affect you this year, not every possible future case.
- Purpose: see risk early and avoid rebuilding your timeline later.
- Minimum required inputs: expected jurisdictions, travel/work dates, the specific rule you are monitoring, and the source/date for your verification note.
- Pending verification: if the relevant threshold is unconfirmed, mark it as pending until you verify the live rule for your jurisdiction and client-location context.
- Done for now: one simple tracker updated weekly, including where you were and when (for example, home country plus one second country if that is your real pattern).
Treasury#
Create one reliable money trail before you add complexity.
- Purpose: keep business inflows/outflows visible, searchable, and consistent.
- Minimum required inputs: one payment/account path you use for business activity, confirmation of product-fit/terms, and one storage location for monthly exports.
- Pending verification: if separation rules or account-type requirements are unclear, mark the local account-separation requirement as pending.
- Done for now: business transactions run through that channel, and monthly exports are saved in the same place as related invoice records.
Before you move to Step 2, run one readiness check: can you produce a mini audit file for one client cycle with rule notes, invoice record, payment record, and residency records that matter this year? If yes, keep operating this baseline and evolve only when a real trigger appears.
If you want a deeper dive, read GDPR for Freelancers: A Step-by-Step Compliance Checklist for EU Clients.
Step 2: Evolve Your System with Real-World Feedback Loops#
Use a trigger-based loop, not a redesign. When something changes in real life, make the smallest verified update to your baseline, then get back to operating.
| Signal you observe | Minimum change you make now | What you defer |
|---|---|---|
| You sign a client in a new market | Verify local invoicing, tax treatment, and reporting duties first. Create one checked invoice variant for that client type, then log the rule, source, date checked, and decision in your operating checklist. | Country packs for markets you do not serve yet, copied tax wording, multi-currency setup before volume requires it |
| Your stay in another country is getting longer | Verify the residency or filing rule that may apply. If the threshold is unconfirmed, mark it as pending, then add one tracking field or alert to your residency log once confirmed. | Full multi-country dashboards, speculative future-country analysis, unverified legal assumptions |
| Cross-border account activity grows | Verify whether reporting, recordkeeping, or account-use duties now apply. Add one monitoring step and one evidence folder for statements, exports, and ownership records. | Extra accounts, treasury optimization, or detailed reporting calendars before a verified obligation exists |
Run each scenario in the same sequence:
- Trigger: A real event happens (new market client, longer stay, higher cross-border account activity).
- Required check: Confirm the applicable local invoicing, tax, residency, or reporting rule before editing anything.
- Action: Make one minimum operational change tied to that trigger.
- Owner: You own the decision and update, and you can assign support tasks if needed.
- MVC baseline update: If the change works once in live use, fold it into the checklist; if it fails, log it and return to the last working baseline.
This is Gall's Law in practice: extend a system that already works through testing, learning, and adaptation instead of building a fully complex structure from scratch. Keep the cadence tight: review the trigger, log the change, test once in live use, update the baseline, then stop until the next real signal.
We covered this in detail in A Guide to Spain's 'Ley de Startups' (Startup Law) for Foreign Entrepreneurs.
Step 3: Achieve an "Anti-Fragile" Operation#
An anti-fragile operation does more than recover from disruption; it gets better because of it. Resilient means you absorb a hit and continue. Anti-fragile means you use the hit to improve your baseline so the next response is clearer and faster.
In day-to-day operations, that is the payoff of Gall's Law. Your invoicing, contracts, payment ops, and compliance workflow become tested layers built from live issues, not guesswork. If a client challenges invoice wording, you verify, update the template, and keep the checked note with the date. If contract terms stall on one clause, you revise that clause in your master template instead of rebuilding the whole agreement. Each disruption leaves a usable upgrade behind.
| Operation type | Response to change | Process ownership | Learning speed |
|---|---|---|---|
| Fragile | Breaks or gets improvised | Unclear, spread across memory and scattered notes | Slow, because each issue starts from scratch |
| Resilient | Recovers and returns to baseline | Usually identified, but fixes may stay temporary | Moderate, because lessons are not always standardized |
| Anti-fragile | Improves the baseline after each hit | Clear owner and documented rule updates | Faster, because each issue becomes reusable process |
This also reduces cognitive load and makes shocks less chaotic. Instead of juggling exceptions in your head, you maintain one current invoice version, one contract template with fallback language, one payment evidence folder, and one compliance checklist that reflects real use. When something changes, you are not calm because risk disappears, but because the next step is already defined.
Use a stress-to-upgrade loop:
- Capture the exact failure point.
- Patch the smallest possible step.
- Document the new rule in your MVC baseline.
- Retest it in live use.
If the same issue repeats and the fix still lives only in email or chat, treat it as a warning sign. The goal is not zero risk; it is stronger control under uncertainty through disciplined iteration.
This pairs well with our guide on A Guide to California's 'AB5' Law for Independent Contractors.
Conclusion: You Are the Architect of a Resilient System#
Your next move is not to design the whole operation at once. It is to keep one working baseline in service and extend it only when live work forces the change. That is the practical value of Gall's Law for complex systems. It is not a style preference. It is a warning that complex setups designed from scratch tend not to work, and more patching or more resources do not reliably rescue them later.
That matters because complexity grows faster than it looks. Even with 10 components, you already have 45 pairwise interactions to manage. At 100 components, you are near 5,000. So the real contrast is not "simple versus sophisticated." It is overdesigning for hypotheticals versus iterating from a baseline that already functions. If you do not yet have a working base, feedback loops have nothing to operate on.
In practice, your baseline can stay small and still be professional. Start with one live process you actually use, one current log of what changed and when, and one clear place to review your records. Those choices matter because you can verify them. Can you run the current version without hunting through old drafts? Can you point to the latest update in your log? Can you trace key activity in one clear history? If not, do not add another layer yet. Tighten the baseline first.
A common failure mode is mistaking preparation for control. You add alternate templates, extra folders, exception rules, and backup tools for situations that do not exist yet. Then the real work arrives, and your attention goes to maintaining the setup instead of serving the client. If a rule is hypothetical, leave it out. If it keeps showing up in live work, it has probably earned a place in your baseline.
If complexity starts knocking, use a simple rule:
- Trigger: a real event changes the facts.
- Decision: make the smallest change that keeps the current baseline working.
- Update: revise the live template or note, record what changed, and avoid side versions in email or chat.
That is how you keep complexity earned instead of assumed. You are not trying to predict every future case. You are building from something that already works, then extending it through testing, learning, and adaptation. Keep that rule close in day-to-day operations, and your admin choices stay tied to evidence and current obligations rather than guesswork.
For a step-by-step walkthrough, see A guide to the 'Common Law' vs. 'Civil Law' systems for international contracts.
Frequently Asked Questions
Should you design the whole operation before you have real demand?
No. Without real demand or real delivery feedback, most of that planning is still assumption. Start with one working path end to end, then expand after it proves itself. If setup is taking longer than delivering initial value, you are likely adding complexity too early.
What is the minimum you should have ready first?
Get the critical pieces right in a small first release. Define one workflow you can run reliably, one clear owner for each step, and one place to keep the records you actually use. Your checkpoint is simple: can the team complete the core cycle correctly and repeat it without confusion? If not, simplify before adding new layers.
How much process work is enough right now?
Scope it to current facts, not future possibilities. Document only the requirements and risks that can change your next action, then verify and update those as work evolves. A common failure mode is designing for multiple hypothetical scenarios before one real scenario is stable.
When should you add another layer?
Add complexity only when live work creates a real trigger: repeated edge cases, a recurring handoff failure, or a new requirement that the current baseline cannot handle. When that happens, change the smallest possible part and keep the update explicit. If the same issue appears twice and the fix still lives only in chat or memory, move it into the baseline immediately. That is the practical value of simple-first design: evolve from a working system instead of trying to launch a fully complex one at once.
Try a related tool
Researched and edited by the Gruv editorial team. Gruv builds cross-border billing, payouts, and finance-operations software for global businesses.
Sources
Includes 2 external sources outside the trusted-domain allowlist.
- app.leg.wa.gov/documents/laws/WACArchive/2005/WAC232.pdftrusted
- pmc.ncbi.nlm.nih.gov/articles/PMC7196013trusted
- pmc.ncbi.nlm.nih.gov/articles/PMC11812118trusted
- regulations.delaware.gov/api/register/October2002/f89eba7f-2631-4afb-...trusted
- scholarship.law.ua.edu/cgi/viewcontent.cgitrusted
- fasterthannormal.co/mental-models/galls-lawexternal
- techmagic.co/blog/galls-lawexternal
Educational content only. Not legal, tax, or financial advice.
Related Posts

GDPR Compliance Checklist for Freelancers Working With EU Clients
Start by separating the decisions you are actually making. For a workable **GDPR setup**, run three distinct tracks and record each one in writing before the first invoice goes out: VAT treatment, GDPR scope and role, and daily privacy operations.

Microservices Architecture for SaaS Without Finance and Compliance Surprises
Choose your operating model before you choose your decomposition pattern. For most early products, that means a modular monolith with clear domain boundaries, not a full microservices setup on day one. The reason is practical. Every new service adds cognitive load, failure points, and maintenance cost, so the split pays off only when your team and controls are ready.

A Guide to the Statement of Work (SOW) for a SaaS Development Project
**Treat your SaaS SOW as a cash flow control system before you treat it as legal paperwork.** If you run a business-of-one, it is one of your core operating controls.